Sigma computing sounds like an analytics topic until a customer asks why their inference job was charged twice, why a transcoding worker returned a corrupt segment, or why a marketplace node passed health checks while silently failing real work.
Teams think the problem is reporting. The real problem is operational truth across jobs, workers, payments, validation, and support.
That changes the conversation. You are not choosing a dashboard. You are designing the control surface for a decentralized compute marketplace where execution is distributed, trust is partial, and every job state can affect settlement.
The practical question is not whether sigma computing can produce charts. The practical question is whether your team can answer, from one workflow, what happened, who did it, how it was validated, what was paid, and what should happen next.
Table of contents
- Sigma computing is an operating model, not a dashboard
- The minimum data model for sigma computing in compute marketplaces
- What to measure before you optimize
- Workflow architecture: from job submit to settlement
- Sigma computing for AI inference workloads
- Sigma computing for FFmpeg transcoding workloads
- What breaks when sigma computing is implemented badly
- What works: practical design patterns
- Build versus buy decisions in 2026
- Product fit: sigma computing on c0mpute.com
- Closing checklist for sigma computing builders
Sigma computing is an operating model, not a dashboard
When the keyword means different things
Sigma computing gets used in a few different ways. Some people mean the Sigma Computing analytics platform. Some mean analytics for compute infrastructure. Some mean a broader operating model for turning raw events into decisions.
For decentralized compute builders, the third meaning is the useful one.
A marketplace that sells AI inference, FFmpeg transcoding, or other compute jobs needs more than a business intelligence layer. It needs a way to reconcile work requested, work performed, work validated, and work paid. If those facts live in separate systems, the marketplace becomes hard to operate as soon as real users arrive.
The mistake teams make is treating sigma computing as a reporting layer added after launch. In production, analytics has to be designed into the job lifecycle.
Why decentralized compute changes the requirements
Centralized infrastructure has one advantage: ownership is obvious. If a job fails, you know which service, account, cluster, queue, or deployment probably owns the failure.
Decentralized compute removes that shortcut. A job may pass through a requester, scheduler, worker, validator, payment module, and support workflow. Different parties may control different parts. A failed job might be a bad input, an unavailable model, a worker misconfiguration, a timeout, a payment authorization issue, or a validation dispute.
A useful way to think about it is this: sigma computing is the operational graph that connects those facts.
If the graph is missing edges, your team guesses. If the graph is complete enough, your team can automate.
The operator view
Operators need a small set of reliable answers:
- What state is this job in right now?
- Which worker accepted it?
- What capability did the worker claim?
- What evidence proves the output was produced correctly?
- What payment state corresponds to the job state?
- Who can retry, refund, slash, or settle?
That is why sigma computing for decentralized compute should start with operational workflows, not visualization preferences. A dashboard is useful only if it reflects the real state machine.
For a deeper adjacent treatment of this topic, the prior c0mpute article on sigma computing for decentralized compute operations frames the same issue around marketplace states, validation, and CLI-first operations.
Practical rule: if a chart cannot lead to a concrete action, it is probably not an operator metric yet.
The minimum data model for sigma computing in compute marketplaces

Jobs are the primary ledger
In a compute marketplace, the job is the unit that ties everything together. Users do not buy abstract capacity. They submit a job with inputs, constraints, expected outputs, and a payment condition.
Your sigma computing model should make the job the primary ledger record.
At minimum, a job record needs:
- job_id
- requester_id or DID
- workload_type, such as inference or transcode
- input_reference and input_hash when possible
- requested_capabilities
- accepted_worker_id
- state
- state_reason
- created_at, accepted_at, started_at, completed_at
- validation_status
- payment_status
- settlement_reference
The practical question is not whether you store all of this in one table. You probably should not. The practical question is whether every operator workflow can reconstruct this view without manual joins across logs, wallets, queues, and support tickets.
Workers need identity and capability context
Worker metrics without identity context are not enough. A worker that completes 1,000 jobs might be reliable, or it might be accepting only trivial work. A worker with a high failure rate might be bad, or it might be taking the hardest jobs.
Worker records need to include claimed and observed capability:
- hardware class
- model availability
- codec support
- memory limits
- region or latency zone
- price terms
- reputation score
- recent failure patterns
- validation history
For AI workloads, capability means model and runtime context. For transcoding, it means codec, bitrate ladder, hardware acceleration, and output format support. For payment-sensitive workflows, it also means identity and settlement eligibility.
Payments cannot be separated from execution
Payments are not a side effect. They are part of the job state machine.
If the worker completes the job but payment settlement fails, the job is not operationally complete. If a payment is authorized but the job never starts, the requester needs a release or refund path. If a validator disputes output, settlement must pause or branch.
Related reading from our network: teams building compute-backed checkout flows face similar state and settlement tradeoffs in cloud computing peptide payments architecture, even though the workload domain is different.
For decentralized compute, the payment model should support:
- quote creation
- authorization or escrow
- job acceptance
- execution proof
- validation
- settlement
- refund or dispute
Practical rule: never let payment status and job status drift without an explicit reconciliation process.
What to measure before you optimize
State transitions beat vanity metrics
The first useful sigma computing metrics are state transition metrics. They tell you where work slows down or falls out of the system.
Track counts and rates for transitions like:
- submitted to quoted
- quoted to authorized
- authorized to accepted
- accepted to started
- started to completed
- completed to validated
- validated to settled
- any state to failed
- any state to disputed
This gives operators a pipeline view. If submitted jobs are not being accepted, you may have supply, pricing, or routing problems. If completed jobs are not validating, you may have output quality or validator capacity problems. If validated jobs are not settling, you have a payment or ledger issue.
The mistake teams make is starting with total jobs and revenue. Those numbers matter, but they do not explain where the system is breaking.
Latency needs percentiles and phases
Average latency is usually a trap. It hides the jobs that create support tickets.
Break latency into phases:
- queue latency
- worker acceptance latency
- startup latency
- execution latency
- upload or output transfer latency
- validation latency
- settlement latency
Then measure percentiles by workload type, model, codec, worker class, and payment path. A marketplace can look healthy at the aggregate level while one model, one codec, or one worker cohort is failing badly.
A good operator view answers: are users waiting because demand exceeds supply, because workers are slow to accept jobs, because validation is backed up, or because settlement is blocked?
Trust metrics need evidence
Trust is not a marketing label. In a decentralized compute marketplace, trust should be derived from evidence.
Useful trust signals include:
- successful completion rate by workload class
- validation pass rate
- dispute rate
- retry rate after worker failure
- output hash consistency
- time since last successful health check
- time since last real job completion
- slashing or penalty history
A worker that pings your control plane every minute is not necessarily trustworthy. What matters is whether it can complete real jobs under the terms it advertises.
Workflow architecture: from job submit to settlement
A practical implementation sequence
A sigma computing architecture should mirror the operational path of a job. Start simple, but make the state transitions explicit.
One practical sequence looks like this:
- Requester submits a job with workload type, input reference, constraints, and maximum price.
- Marketplace creates a quote and assigns a durable job_id.
- Payment module authorizes funds, escrow, or spend permission.
- Scheduler matches the job to eligible workers.
- Worker accepts the job and emits an acceptance event.
- Worker starts execution and emits progress events.
- Worker uploads output and emits completion metadata.
- Validator checks the output and records evidence.
- Payment module settles, refunds, or opens dispute.
- Marketplace writes final job state and exposes it to CLI, API, and support workflows.
This is not complicated on paper. What breaks in practice is that teams skip durable events and rely on whatever state their queue, wallet, or worker logs happen to expose.
Idempotency and retries are not optional
Distributed compute means retries. Retried submissions, retried webhook deliveries, retried worker uploads, retried payment callbacks, retried validator checks.
Without idempotency, retries create duplicate jobs, duplicate charges, duplicate outputs, or inconsistent settlement.
Use idempotency keys for:
- job submission
- quote acceptance
- payment authorization
- worker acceptance
- output upload
- validation result
- settlement request
A minimal event shape can be boring and still effective:
event_id: evt_01
job_id: job_01
event_type: worker.completed
producer: worker_did_abc
occurred_at: 2026-06-08T10:15:00Z
idempotency_key: job_01:worker.completed:v1
payload_hash: sha256:...
The key is not the exact format. The key is that every consumer can safely process the same event more than once.
Practical rule: design every state transition as if the message will be delivered twice and observed out of order.
Where CLI workflows fit
CLI-first teams should not treat analytics as a separate web-only surface. Operators need fast, scriptable access to job state.
A useful CLI operating loop might include:
compute jobs submit transcode input.mp4 --profile hls-1080p
compute jobs inspect job_01
compute jobs events job_01 --tail
compute workers inspect worker_did_abc
compute payments inspect job_01
compute jobs retry job_01 --from validation
The CLI is not just developer convenience. It is how you make the operating model testable. If your dashboard shows a state that your CLI cannot explain, the dashboard is probably hiding complexity.
Builders evaluating c0mpute can use the c0mpute docs as a reference point for CLI-oriented workflows around identity, workers, transcode jobs, inference, plugins, and health checks.
Sigma computing for AI inference workloads
Capture model and prompt context safely
AI inference creates a specific analytics problem: the input may be sensitive, large, or not safe to log directly.
A good sigma computing design captures enough context to debug and price the job without turning your analytics store into a prompt leak.
Capture:
- model identifier
- model version or digest
- runtime configuration
- token counts or input size
- output size
- sampling parameters when relevant
- safety or policy outcome
- prompt hash instead of raw prompt when possible
- encrypted reference to raw input when needed
Avoid dumping raw prompts into general-purpose logs. Operators need to know which model ran, what it cost, how long it took, and whether it passed policy. They do not always need the full input in every analytics view.
Validate outputs without pretending it is easy
Inference validation is harder than transcoding validation because many outputs are probabilistic. You can validate that a worker returned a response, used the expected model endpoint, and stayed within time and size constraints. Validating semantic quality is a different problem.
Do not pretend one metric solves it.
Useful validation layers include:
- schema validation for structured outputs
- deterministic checks for tool calls
- policy checks for disallowed content
- similarity or embedding checks for specific tasks
- spot checks by trusted validators
- requester feedback after delivery
Sigma computing should expose which validation layer passed or failed. A single validation_status field is useful for operators, but it should link to more detailed evidence.
Cost visibility across providers
AI infrastructure builders often route across providers, models, accelerators, and worker classes. Cost visibility needs to follow that routing.
Track cost dimensions such as:
- model family
- token usage
- GPU class
- worker price
- marketplace fee
- retry cost
- validation cost
- refund or dispute cost
The practical question is not just which provider is cheaper. It is which route produces acceptable latency, output quality, validation pass rate, and settlement reliability for a given price.
Sigma computing for FFmpeg transcoding workloads
Segment the pipeline into observable stages
FFmpeg jobs are easier to validate than open-ended inference, but they still fail in ways that dashboards often miss.
A transcode job can include:
- input fetch
- probe
- decode
- filter graph
- encode
- segment
- package
- upload
- manifest validation
- playback check
If you treat this as one job duration and one exit code, you lose the ability to diagnose where time and failure actually occur.
Related reading from our network: video infrastructure teams deal with similar ingest, transcoding, caching, and observability boundaries in cloud computing IPTV architecture.
Compare outputs, not just exits
FFmpeg exit code 0 is not the same as a usable asset. A worker can produce an output file that is technically complete but wrong for the requester.
Validate outputs with checks like:
- expected codec
- expected resolution ladder
- duration match within tolerance
- audio stream presence
- manifest references exist
- segment count is plausible
- bitrate ranges are acceptable
- output hash recorded
This is where sigma computing becomes operationally valuable. You can correlate failure with codec, input format, worker class, FFmpeg version, or hardware acceleration mode.
Capacity planning for bursty media jobs
Video workloads are bursty. A batch of uploads can saturate workers that look idle five minutes earlier.
Measure capacity in terms that match work:
- queued media minutes
- real-time factor by profile
- encoder class availability
- average and p95 output upload time
- storage egress pressure
- validator backlog
For media systems, job count alone is misleading. Ten short clips are not the same as ten long 4K inputs. Your sigma computing model needs workload weight, not just workload count.
What breaks when sigma computing is implemented badly
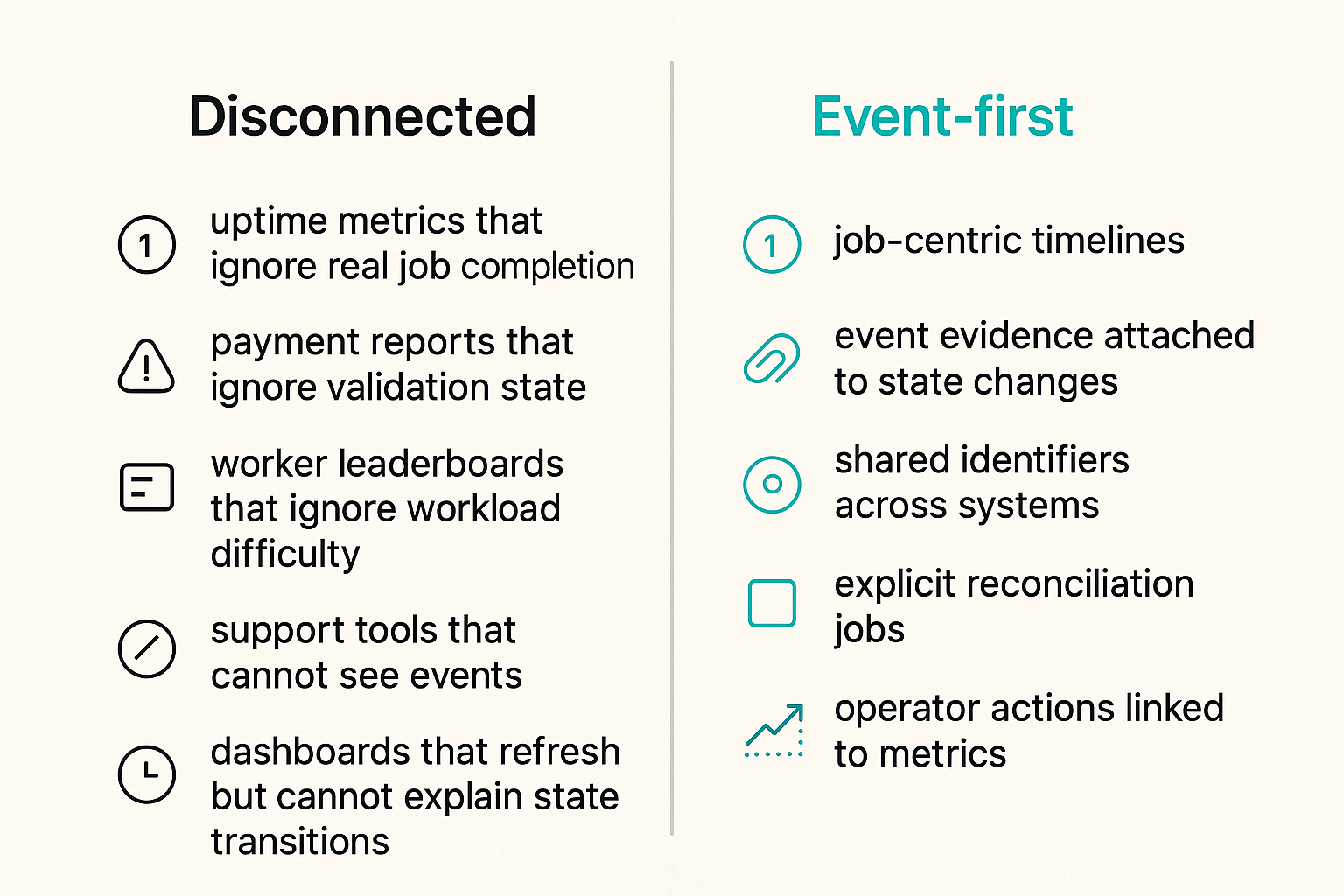
Disconnected dashboards create false confidence
The most common failure mode is a dashboard that looks clean because it ignores the messy parts.
One dashboard shows worker uptime. Another shows job counts. A wallet explorer shows payments. A queue shows pending tasks. Support has screenshots from users. None of them agree on the state of a specific job.
That creates false confidence. Leadership sees green charts while operators are manually reconstructing timelines in chat.
What fails:
- uptime metrics that ignore real job completion
- payment reports that ignore validation state
- worker leaderboards that ignore workload difficulty
- support tools that cannot see events
- dashboards that refresh but cannot explain state transitions
What works:
- job-centric timelines
- event evidence attached to state changes
- shared identifiers across systems
- explicit reconciliation jobs
- operator actions linked to metrics
Missing ownership slows incident response
A decentralized marketplace still needs ownership. Distributed execution does not mean distributed accountability.
Every state transition should have an owning component and an escalation path. If validation is delayed, who owns it? If settlement fails, who owns it? If a worker accepts a job and disappears, who owns the timeout policy?
Without ownership, sigma computing turns into observation without control.
A practical ownership map includes:
- scheduler owns matching and acceptance timeout
- worker runtime owns execution progress
- validator owns evidence and validation result
- payment module owns authorization and settlement
- support operator owns manual customer resolution
- governance or policy module owns penalties and disputes
Bad schemas become operational debt
Early schemas often reflect whatever was fastest to ship. That is normal. The danger is letting those schemas become the permanent source of truth.
Watch for these schema smells:
- status values with unclear meanings
- failed state used for every error
- no separate retry_attempt field
- no state_reason
- no actor identity on state changes
- no distinction between user cancellation and system failure
- no link between payment event and job event
Related reading from our network: teams trying to make infrastructure content legible to AI crawlers run into a similar metadata problem, where structure determines whether systems can interpret the page at all; see cloud computing answer engine optimization.
The same principle applies operationally. If machines cannot interpret your job states, humans will be stuck interpreting them manually.
What works: practical design patterns
Event first, report second
The strongest pattern is event-first design. Reports are derived. Events are the operational record.
An event-first marketplace can rebuild views, debug incidents, add metrics, and reconcile downstream systems. A report-first marketplace can only show whatever someone decided to aggregate last month.
Events should be:
- durable
- timestamped
- actor-attributed
- idempotent
- versioned
- linked by job_id
- safe to replay
This does not mean every event needs to go on-chain. Most operational events do not belong on-chain. It means your internal architecture should preserve the sequence of meaningful facts.
Separate control plane and analytics plane
Do not let analytics queries become part of the critical execution path.
The control plane should make job routing, validation, and payment decisions from operational stores designed for correctness and latency. The analytics plane should consume events and produce operator views, cohort analysis, cost reports, and anomaly detection.
The two planes should agree on identifiers and state definitions, but they should not be the same system.
This separation lets you:
- keep job execution fast
- run heavier analysis safely
- backfill reports after schema changes
- isolate dashboard failures from job execution
- expose different access controls for operators and analysts
Keep human override paths
Automation is useful until it confidently does the wrong thing.
Human override paths matter in decentralized compute because edge cases involve money, reputation, and customer trust. An operator may need to mark a job as refunded, force validation review, quarantine a worker, or replay settlement.
Good override paths are audited. Bad override paths are ad hoc database edits.
A good override event includes:
- operator identity
- affected job_id
- previous state
- new state
- reason
- linked evidence
- timestamp
- whether requester or worker was notified
Practical rule: any manual action that changes money, reputation, or job state must emit an event like any automated action.
Build versus buy decisions in 2026
When a warehouse first approach is enough
A warehouse-first approach can work when your marketplace is early, volume is low, and most workflows are still human-operated.
You can stream events into a warehouse, define job lifecycle views, and build dashboards for operations. This is often the right starting point because it forces the team to define states and identifiers without prematurely building a complex internal platform.
It works when:
- job volume is manageable
- settlement is simple
- disputes are rare
- workers are mostly trusted
- operators can tolerate some delay
- the team has strong SQL and data modeling habits
The danger is assuming the warehouse is the control plane. It is not.
When you need marketplace native telemetry
You need marketplace-native telemetry when decisions must happen during execution.
Examples:
- route away from workers with rising validation failures
- pause settlement on suspicious output
- detect duplicate submissions before charging
- enforce worker timeout policies
- adjust pricing based on capacity
- quarantine a worker after repeated corrupt outputs
At that point, sigma computing cannot be just downstream reporting. It needs to feed the operational loop.
A common architecture is:
- event bus for state changes
- operational store for current state
- analytics store for history and reporting
- policy engine for automated actions
- CLI and API for operator control
Comparison table
| Approach | What works | What fails | Best fit |
|---|---|---|---|
| Dashboard after launch | Fast to show basic metrics | Misses state transitions and payment drift | Demos and very early prototypes |
| Warehouse first | Flexible analysis and backfills | Too slow for real-time control | Early marketplaces defining their model |
| Event-first operations | Strong auditability and replay | Requires discipline in schema design | Production decentralized compute |
| Marketplace-native telemetry | Enables automated routing and settlement controls | More engineering surface area | High-volume or payment-sensitive networks |
The mistake teams make is jumping straight to marketplace-native telemetry without defining the state model. The opposite mistake is staying dashboard-only after money and reputation are already moving through the system.
Product fit: sigma computing on c0mpute.com
Mapping analytics to modules
c0mpute.com is built around practical decentralized compute workflows: transcode for FFmpeg jobs, infernet for AI inference, and coinpay for DID-based payments. That maps naturally to the sigma computing model described here.
The architecture view is straightforward:
- transcode emits media pipeline and output validation events
- infernet emits model, runtime, latency, and response metadata
- coinpay links identity, authorization, escrow, and settlement state
- worker reputation connects execution evidence to future routing
- CLI workflows expose job and worker state to operators
This is the important part: the UI is not the system. The system is the state machine that connects compute and payment.
A CLI first operating loop
CLI-first infrastructure teams need workflows that can be scripted, tested, and repeated. A browser dashboard is useful for scanning. It is not enough for incident response or automation.
A practical c0mpute-style loop looks like:
- Submit a job from CLI.
- Inspect assigned worker and terms.
- Tail lifecycle events.
- Validate output evidence.
- Inspect payment state.
- Retry, dispute, or settle with an auditable command.
That loop matters because decentralized compute operations often happen at the boundary between engineering and support. The same command surface that helps a developer test a job can help an operator resolve a customer issue.
Where c0mpute.com fits
c0mpute.com is not trying to turn compute operations into vague dashboards. The useful fit is more specific: give builders a CLI-first decentralized compute network where inference, transcoding, identity, and payments are treated as connected workflows.
That makes sigma computing less abstract. Instead of asking what charts to build, you ask which job events, worker signals, validation evidence, and payment transitions must exist for the marketplace to operate safely.
If those primitives are present, dashboards become easier. More importantly, automation becomes safer.
Closing checklist for sigma computing builders
Questions to answer before launch
Before launching a decentralized compute marketplace, answer these questions plainly:
- What is the canonical job_id across every system?
- What are the allowed job states?
- Which actor can move a job between states?
- Which events are idempotent?
- How is payment state linked to execution state?
- What evidence proves a worker completed the job?
- What happens when validation fails?
- What happens when settlement fails?
- Can support inspect a full job timeline?
- Can operators replay or reconcile events safely?
- Can workers be quarantined based on evidence?
- Can users understand whether a failure is input, capacity, validation, or payment related?
If the answers are unclear, the system is not ready for serious volume.
The practical next step
Start by modeling one workload end to end. Do not model the whole marketplace in the abstract.
For AI inference, model submitted to settled, including validation and retry. For FFmpeg transcoding, model input fetch to output validation and payment. For DID-based payment, model authorization to refund or settlement.
Then build the operator view from those events. That is sigma computing in the sense that matters for decentralized compute builders: not a prettier dashboard, but a reliable operating model for work, trust, and money.
In 2026, the teams that win will not be the teams with the most charts. They will be the teams that can explain and control every important transition in the compute lifecycle.
Try c0mpute.com
c0mpute.com is for technical builders interested in decentralized compute, AI inference, FFmpeg transcoding, and DID-based payments. Try c0mpute.com.