Quantum computing inc announcements land in developer feeds every few weeks. New qubit counts, new error correction milestones, new cloud access endpoints. Most web3 and AI infrastructure builders skim them and move on, because nothing in the announcement maps cleanly to what they're actually building.
That's the wrong reaction — not because quantum supremacy is imminent for your workloads, but because quantum computing inc developments are already reshaping the assumptions behind decentralized compute architecture. Key exchange protocols, job routing heuristics, proof verification, and inference acceleration are all in motion. The builders who ignore this until it's critical will face expensive retrofits.
Teams think the problem is whether quantum computers can run their workloads today. The real problem is whether the compute routing and cryptographic primitives in your current architecture will hold under a post-quantum threat model — and whether your job dispatch layer is flexible enough to incorporate quantum backends when they become economically viable for specific task classes.
This guide is about that architecture problem: not quantum hype, but the concrete decisions decentralized compute builders need to make now.
Table of contents
- What quantum computing inc actually changes for builders
- The cryptographic exposure problem
- Compute routing architecture under a hybrid model
- Job validation and proof systems
- Payment and settlement under post-quantum assumptions
- AI inference routing decisions
- FFmpeg transcoding and classical compute persistence
- Failure modes in production
- What works and what fails
- Architecture checklist before you route a quantum job
- How c0mpute fits into a quantum-aware decentralized compute stack
What quantum computing inc actually changes for builders
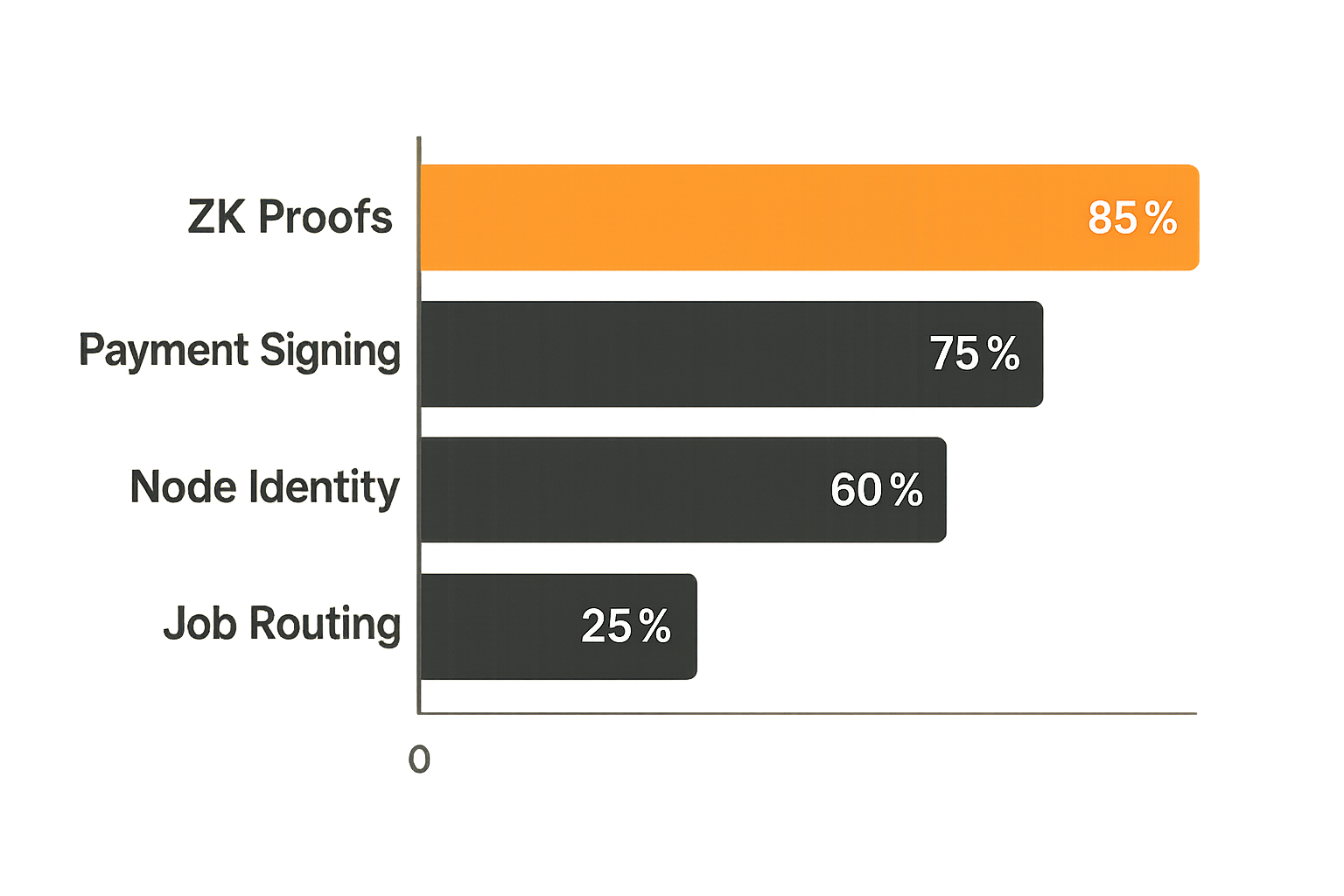
The framing most teams use is wrong. They ask: "Can a quantum computer run my ML training job?" That question has a boring answer (not yet, for most jobs). The useful question is: "Which components of my compute stack are quantum-sensitive, and on what timeline?"
Quantum computing inc milestones matter to builders through three channels: cryptographic protocol obsolescence, optimization problem acceleration, and new backend availability through cloud APIs. Each of these has a different urgency and a different remediation path.
Workload classes that matter today
Right now, the quantum computing inc developments that affect decentralized compute builders are almost entirely cryptographic. Shor's algorithm running on fault-tolerant hardware at scale breaks RSA and elliptic-curve cryptography. That's not hypothetical pressure anymore — it's a migration timeline question.
If your compute marketplace uses secp256k1 for node identity, job signing, or payment authorization — which most Ethereum-adjacent stacks do — you have exposure. The question isn't "if" but "when your threat model requires you to act."
For AI inference routing, quantum annealing approaches (D-Wave-style) are already commercially accessible and provide real speedups on certain combinatorial optimization problems: bin-packing, scheduling, and graph partitioning. Job dispatch in a large decentralized network is exactly this class of problem.
Workload classes that matter in 12–24 months
Over the next two years, watch two areas. First, quantum-assisted optimization for routing tables in decentralized compute networks — the traveling-salesman-adjacent problem of assigning heterogeneous jobs to heterogeneous nodes under latency and cost constraints. Classical heuristics work fine at small scale; they degrade badly at thousands of nodes.
Second, quantum random number generation (QRNG) as a service. Many cryptographic protocols in decentralized systems rely on pseudo-randomness. QRNG services from quantum computing inc providers are already accessible via API and provide certifiably non-deterministic entropy. For high-value job auctions and payment nonces, this matters.
Practical rule: Audit your stack by asking which components use asymmetric cryptography for signing, verification, or key exchange. Those are your quantum exposure surface. Everything else is secondary.
The cryptographic exposure problem

The cryptographic exposure problem is where quantum computing inc intersects most urgently with decentralized compute architecture. Most builders think about this too late — after the stack is already wired around a specific key scheme.
Where decentralized compute stacks are exposed
A typical decentralized compute stack has cryptographic dependencies in more places than teams realize:
- Node identity: public/private keypairs used to authenticate workers to the network
- Job signing: client-signed job manifests that workers verify before accepting work
- Payment authorization: signatures over payment transactions, often EVM-compatible
- TLS between components: session key exchange on control-plane APIs
- ZK proof generation and verification: elliptic-curve pairings in Groth16 and PLONK circuits
Each of these uses cryptographic primitives that Shor's algorithm targets. The ZK proof systems are particularly exposed because they rely heavily on elliptic curve pairings over specific curves (BN254 is common) — and retrofitting a ZK system to use post-quantum primitives is not a configuration change, it's a circuit rewrite.
Post-quantum key exchange in practice
NIST finalized its first post-quantum cryptography standards in 2024: CRYSTALS-Kyber for key encapsulation, CRYSTALS-Dilithium and FALCON for digital signatures. The practical question for decentralized compute builders is how to introduce these without a flag-day migration.
The answer is hybrid key exchange: run classical and post-quantum algorithms in parallel, requiring an attacker to break both. OpenSSL 3.x supports this. Cloudflare's CIRCL library provides Go implementations. For most decentralized compute control planes, a hybrid TLS upgrade is a 1–2 week engineering project with minimal protocol surface changes.
For on-chain payment signatures (EVM-compatible), the migration is harder because it requires smart contract changes. The practical approach is to introduce a wrapper layer: an off-chain settlement service that handles job payment authorization with post-quantum signatures, settling to chain in batches. Related reading from our network: teams building secure identity and messaging systems face similar key lifecycle tradeoffs — the workflow architecture patterns described for VA secure messaging apply directly to how you structure key rotation and device trust in a distributed compute context.
Practical rule: Don't wait for a monolithic post-quantum migration. Introduce hybrid key exchange at your control plane first — it's the highest-leverage, lowest-disruption starting point.
Compute routing architecture under a hybrid model
Classical versus quantum routing heuristics
The practical question for job routing is: at what scale does a quantum optimization backend start to beat your classical routing heuristics? The answer depends heavily on problem structure.
For a network under 500 nodes with reasonably homogeneous job types, classical heuristics (weighted round-robin, capability matching, latency scoring) are sufficient and significantly cheaper. The overhead of submitting an optimization problem to a quantum annealing API, waiting for a result, and incorporating it into dispatch decisions adds latency that hurts short-horizon jobs.
For networks above 1,000 nodes with heterogeneous job types (mix of GPU inference, CPU transcoding, specialized accelerators) and strong latency-cost tradeoffs, quantum-assisted scheduling starts to show measurable improvement on batched dispatch decisions — not real-time routing, but multi-second planning horizons.
| Routing approach | Best fit | Latency overhead | Complexity |
|---|---|---|---|
| Weighted round-robin | <200 nodes, homogeneous jobs | ~0ms | Low |
| Capability-scored dispatch | <500 nodes, mixed jobs | <5ms | Medium |
| Classical optimizer (LP/ILP) | <1,000 nodes, batched planning | 50–500ms | Medium-high |
| Quantum annealing (D-Wave/QAOA) | >1,000 nodes, batched planning | 1–5s | High |
| Hybrid classical+quantum | Large networks, tiered decisions | Varies | High |
The mistake teams make is treating quantum routing as a drop-in upgrade to their existing dispatch layer. It isn't. It requires a fundamentally different problem formulation — you're encoding your routing constraints as a QUBO (Quadratic Unconstrained Binary Optimization) problem, which requires reformulating soft constraints you've been expressing as code logic.
Fallback and degraded-mode design
Any architecture that incorporates a quantum computing inc API call in a critical path must have a classical fallback. Quantum cloud APIs have availability characteristics that differ from classical compute APIs — queue depths, calibration windows, backend maintenance. You cannot build a hard dependency on quantum dispatch for real-time job routing without degraded-mode logic.
The pattern that works: use quantum optimization for planning-horizon decisions (next 30–60 seconds of job allocation), while classical heuristics handle moment-to-moment dispatch. If the quantum planning call fails or exceeds timeout, the classical layer runs independently.
Practical rule: Quantum backends should always be in the optimization path, never in the critical path. Design for classical-first with quantum as an accelerant.
Job validation and proof systems
Why ZK proofs are affected first
Zero-knowledge proof systems are the component of decentralized compute infrastructure most immediately affected by quantum computing inc advances. Most production ZK systems use BN254 or BLS12-381 elliptic curves. These are vulnerable to quantum attacks at a lower qubit threshold than RSA-2048, because the discrete logarithm problem on these specific curves may fall to quantum algorithms faster than expected.
For decentralized compute, ZK proofs appear in several places: proof of compute execution (verifiable compute), proof of storage, payment channel state transitions, and reputation attestations. Any of these that rely on BN254 have a migration runway to plan.
Validation pipeline redesign
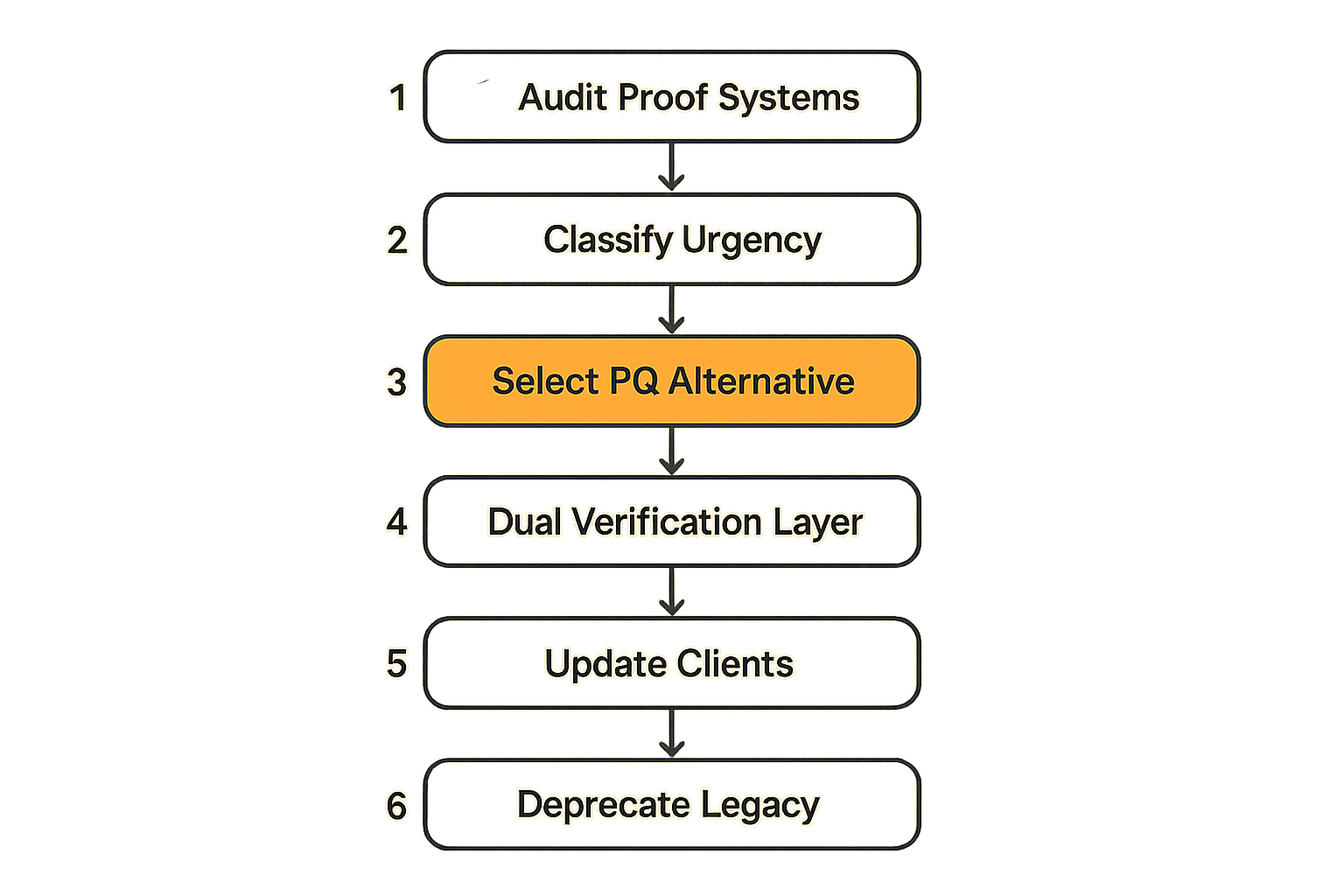
The practical sequence for making a validation pipeline quantum-resistant:
- Audit which proof systems are in use — list every place a ZK proof is generated or verified, and which curve/backend it uses.
- Classify by urgency — proofs over high-value payment state transitions are urgent; reputation attestations are lower priority.
- Identify post-quantum alternatives — STARKs are quantum-resistant by construction (they use hash functions, not elliptic curves). For systems currently using SNARKs, a STARK migration is the cleanest path.
- Build a dual-verification layer — accept both old SNARK and new STARK proofs during a transition window, with a sunset date for legacy format.
- Update your proof generation clients — this is often the hardest step because clients are distributed and you don't control upgrade timing.
- Deprecate the old verification path — after the transition window closes.
This is a months-long project for a production system. Teams that wait until quantum hardware is actually threatening their curves will be doing this under pressure.
Payment and settlement under post-quantum assumptions
DID-based payment flows and key lifecycle
DID-based payment flows — where worker nodes and clients are identified by decentralized identifiers backed by keypairs — have a structural advantage for post-quantum migration: the DID document can be updated to advertise new key types without changing the identifier itself. This is one of the real practical benefits of the DID architecture for long-lived infrastructure.
The c0mpute.com decentralized compute marketplace uses DID-based identity for node registration and job authorization. The implication for post-quantum migration is that you can introduce a new verification method in the DID document — a Dilithium public key alongside the existing secp256k1 key — and start signing new job authorizations with both. Verifiers that understand both methods can enforce the stronger requirement; legacy verifiers fall back to the classical key.
Key lifecycle management is where this gets operationally complex. DID key rotation requires broadcasting a DID document update, waiting for resolution propagation, and ensuring all in-flight job authorizations use the correct key version. In a high-throughput compute marketplace, this means your job signing layer needs to be key-version-aware, not just key-aware.
Settlement finality and replay risk
Under a post-quantum threat model, "harvest now, decrypt later" attacks become relevant for settlement proofs. An attacker can record signed settlement transactions today and decrypt or forge them when quantum hardware is sufficiently capable. For compute jobs where settlement happens on a public chain, every signed transaction is a permanent record.
The practical mitigation is short-lived settlement tokens with tight expiry windows, combined with a nonce structure that prevents replay even if a signature is eventually forged. This is standard replay-protection practice, but many teams implement it loosely. The quantum threat model makes "good enough" nonce hygiene into a hard requirement.
AI inference routing decisions
Where quantum backends add value for inference
For AI inference specifically, the quantum computing inc angle is less about running transformer inference on quantum hardware (that's distant) and more about two adjacent capabilities: quantum-optimized hyperparameter search and quantum-enhanced feature selection for smaller models.
For decentralized inference routing, the near-term value is in job scheduling optimization — the same bin-packing and scheduling problems discussed earlier. A GPU node serving inference requests has heterogeneous capacity that changes second-to-second. Routing inference jobs to minimize latency and maximize utilization across a large pool is a hard combinatorial problem that quantum annealing approaches handle well.
For teams building on top of c0mpute's CLI-first compute network, the inference routing layer is an extensible plugin point. When quantum-optimized scheduling backends become cost-competitive, they can be integrated as routing strategy plugins without rewriting the job dispatch interface.
What breaks when you naively hybridize
The failure mode teams hit most often: they add a quantum optimization call to their routing layer without accounting for the latency distribution of quantum API responses. Classical routing decisions happen in microseconds to milliseconds. Quantum optimization API calls return in seconds to tens of seconds. If your inference serving infrastructure expects sub-100ms routing decisions, inserting a synchronous quantum optimization call breaks your latency SLA.
The fix is asynchronous planning: the quantum optimizer runs on a planning horizon ("what's the best allocation for the next batch of jobs") while the synchronous routing layer uses the most recent plan. The quantum optimizer updates the plan continuously in the background. This is architecturally similar to how many ML-based traffic routing systems work — a fast inference path that uses a periodically-updated model, with the model update happening off the critical path.
FFmpeg transcoding and classical compute persistence
Why transcoding stays classical longer
Video transcoding with FFmpeg is a workload that will remain on classical compute longer than almost any other workload in a decentralized compute stack. The reason is structural: FFmpeg and the codecs it wraps (H.264, H.265, AV1, VP9) are built around bit-manipulation operations that map efficiently to classical CPU and GPU SIMD instruction sets. There's no meaningful quantum speedup for this class of computation.
Quantum hardware accelerates workloads where the problem structure maps to quantum superposition and entanglement — optimization, simulation, and certain linear algebra operations. Video encoding is fundamentally a sequential, data-dependent process with tight feedback loops between frames. It's a poor fit for quantum parallelism.
This is useful to know because it means your transcoding infrastructure decisions can be made entirely on classical compute economics — GPU availability, per-core pricing, codec support — without worrying about quantum disruption on the workload itself. The quantum exposure for transcoding is indirect: key exchange and job signing for the transcoding job marketplace, not the encode itself.
Encoding pipeline resilience patterns
For decentralized FFmpeg transcoding pipelines, resilience comes from job idempotency and state checkpointing, not from quantum concerns. The practical patterns:
- Idempotent job IDs: Every transcode job gets a content-addressed ID (hash of input + encode parameters). Re-submitting the same job is a no-op if output already exists.
- Segment-level checkpointing: For long-form video, transcode in fixed-duration segments. A failed worker hands off at segment boundaries, not mid-file.
- Output validation before settlement: Don't settle payment for a transcode job until a second worker validates a sample of the output frames meet quality thresholds.
- Capability-tagged worker selection: Workers advertise codec support and GPU model. The router only dispatches AV1 jobs to workers with AV1 hardware encoders.
Failure modes in production
The partial-migration trap
The most dangerous failure mode when integrating quantum computing inc capabilities into a decentralized compute stack is the partial migration. A team updates TLS to use hybrid post-quantum key exchange on the control plane, but leaves job signing using secp256k1. They now have a system that's quantum-resistant at the transport layer but still vulnerable at the application layer — and worse, they think they've addressed the problem.
Partial migrations create false security confidence. The audit question isn't "have we started migrating" but "what is the weakest cryptographic link in the chain of trust from client job submission to on-chain settlement?" That chain needs to be traced end-to-end, and every link audited, before you can claim meaningful post-quantum hardening.
Related reading from our network: teams building interactive and agent-driven workflow architectures face similar partial-migration traps with identity and state — the architecture patterns discussed for interactive presentation tools as agent workflow surfaces highlight how identity and validation gaps propagate across distributed workflow steps in ways that are hard to catch until production.
Vendor lock-in through quantum cloud APIs
Quantum computing inc providers (IBM Quantum, IonQ, D-Wave, Quantinuum) each have proprietary job submission APIs, circuit formats, and optimization problem encodings. A decentralized compute marketplace that hard-wires against a single quantum cloud API is creating a new form of vendor dependency in infrastructure that was built to avoid it.
The practical mitigation is an abstraction layer: a quantum job adapter interface that accepts a standardized problem specification (QUBO for optimization, OpenQASM for circuit execution) and translates to provider-specific APIs. This adds engineering overhead upfront but preserves provider portability — if a cheaper or more capable provider becomes available, you swap the adapter, not the routing logic.
Practical rule: Any quantum backend integration in a decentralized compute stack needs an abstraction layer with a classical fallback. This is not optional — it's the same principle as not hard-wiring to a single GPU cloud provider.
What works and what fails
Patterns that hold up
- Hybrid key exchange at the control plane: Low disruption, immediately reduces cryptographic exposure. Do this first.
- Asynchronous quantum optimization for job scheduling: Keeps quantum APIs off the critical path while capturing optimization benefits.
- DID document versioning for key rotation: Enables gradual post-quantum key introduction without identifier migration.
- STARK-based proof systems for new verification paths: Quantum-resistant by construction; start new proof requirements on STARKs rather than SNARKs.
- Segment-level checkpointing for transcoding jobs: Improves resilience without quantum dependencies.
- Classical fallback for every quantum API call: Non-negotiable for production availability.
Patterns that collapse
- Synchronous quantum API calls in routing critical path: Destroys latency SLAs.
- Assuming one post-quantum upgrade covers all exposure: Partial migrations create false confidence.
- Hard-wiring to a single quantum cloud provider API: Creates vendor lock-in in infrastructure designed to avoid it.
- Delaying ZK proof system migration until quantum hardware is capable: Migration is months of work; you need runway.
- Treating quantum optimization as a drop-in for classical dispatch: Requires QUBO reformulation of constraints — it's a rewrite, not a config change.
- Ignoring "harvest now, decrypt later" for settlement transactions: Signed transactions on public chains are permanent records.
Architecture checklist before you route a quantum job
Before integrating a quantum computing inc backend into your decentralized compute routing layer, work through this checklist:
- Map your cryptographic surface: List every component using asymmetric cryptography. Classify each as quantum-exposed (RSA, secp256k1, BN254) or quantum-resistant (hash-based, STARK, post-quantum standards).
- Introduce hybrid key exchange on control plane TLS: OpenSSL 3.x + CRYSTALS-Kyber. Set a target completion date.
- Design a QUBO formulation for your routing problem: If you can't formulate your scheduling constraints as a QUBO, quantum annealing won't help you. Do this before evaluating hardware.
- Build a quantum job adapter interface: Standardize on OpenQASM for circuit work, QUBO JSON for optimization. Implement at least two provider backends plus classical fallback.
- Set a planning-horizon architecture: Quantum optimizer runs on 30–60s planning windows. Classical dispatcher uses latest plan. Never synchronous.
- Audit ZK proof systems: Identify all circuits using BN254. Build a migration plan to STARK or post-quantum-compatible curves. Set a sunset timeline for each SNARK-based path.
- Harden nonce and settlement token hygiene: Tight expiry windows, replay-prevention nonces. Treat this as a hard requirement, not a best practice.
- Test classical fallback paths: Intentionally cut quantum API access in staging. Verify classical routing maintains acceptable performance without quantum planning input.
This checklist won't survive contact with your specific stack unchanged — but it covers the structural decisions that determine whether quantum integration helps or creates new fragility. You can track the operational health of your compute jobs as you roll this out using real-time observability like the c0mpute network status page.
How c0mpute fits into a quantum-aware decentralized compute stack
Building post-quantum-aware infrastructure from scratch is expensive. The argument for a decentralized compute marketplace like c0mpute isn't that it solves all quantum migration problems — it's that the architectural decisions c0mpute makes at the platform level (DID-based identity, modular job routing, CLI-first extensibility) align well with the migration patterns described in this guide.
DID-based node identity means key rotation is a first-class operation, not an afterthought. The modular job routing architecture means quantum optimization backends can be introduced as routing plugins without rewriting the dispatch layer. The separation of transcode, inference, and payment modules means you can migrate each cryptographic surface on its own timeline without flag-day changes. The prior work on quantum computing inc architecture patterns for decentralized compute builders covers the foundational routing and validation decisions in more depth if you're mapping this to an existing stack.
For teams building video transcoding pipelines, AI inference APIs, or DID-based payment flows on decentralized infrastructure, the quantum computing inc conversation is ultimately about architectural durability: building systems that don't need to be scrapped when cryptographic assumptions change. That's the same reason you build on composable, modular compute infrastructure instead of monolithic cloud APIs.
The practical next step isn't buying quantum hardware or rewriting your ZK circuits this week. It's auditing your cryptographic surface, choosing an abstraction boundary for quantum backend integration, and making sure your job routing layer can accommodate new backend types without structural changes. That's tractable engineering work, and it positions you to capture quantum optimization benefits when they become economically justified for your workload class. Teams in adjacent niches thinking about AI answer engine optimization and content freshness face similar "build the infrastructure now or retrofit under pressure" decisions — as AEO workflow patterns make clear, the teams that instrument their architecture proactively rarely regret it.
Try c0mpute.com
c0mpute is a decentralized compute marketplace built for technical builders — CLI-first, with modules for FFmpeg transcoding, AI inference, and DID-based payments. If you're building quantum-aware infrastructure on a composable compute layer, start at c0mpute.com.