Quantum computing inc searches usually start with a vendor question. A team wants to know which quantum provider is credible, which SDK to test, or whether quantum hardware is finally useful enough to matter.
That is not the hard part.
Teams think the problem is access to quantum computing inc capabilities. The real problem is building a workflow that can route classical, AI, video, and quantum-adjacent jobs without turning the system into a research demo nobody can operate.
For decentralized compute builders in 2026, the practical question is not whether quantum computing is exciting. It is whether your marketplace, scheduler, identity layer, payment flow, and validation model can absorb a specialized backend with different latency, pricing, and trust assumptions.
A useful way to think about it is this: quantum is not a replacement for your compute network. It is another execution class. That changes the conversation from hype to architecture.
Table of contents
- Why quantum computing inc is an architecture decision
- Where quantum computing inc fits in a decentralized compute marketplace
- The workload split between classical AI video and quantum
- The control plane you need before a quantum computing inc integration
- Data movement and trust boundaries
- Payments settlement and access control for quantum jobs
- Observability for hybrid quantum workflows
- Implementation workflow for builders
- What breaks when teams implement quantum computing inc badly
- Product fit c0mpute.com and hybrid compute routing
- Closing checklist for quantum computing inc decisions
Why quantum computing inc is an architecture decision
Most teams approach quantum computing inc like they approach a new GPU vendor: get access, run an example, compare output, then decide whether to integrate. That path is fine for exploration. It is weak for production.
A quantum backend changes assumptions around queueing, determinism, availability, billing, and result interpretation. Even if the quantum part is small, it sits inside a larger pipeline that still needs classical preprocessing, postprocessing, storage, identity, and support.
The mistake teams make is treating the quantum provider as the system. It is not. The system is the workflow around it.
Workloads do not move as a block
AI infrastructure builders already know this pattern. A request may hit an API gateway, pass through auth, route to a model, stream tokens, log usage, trigger billing, and retry failed segments. Video engineers see the same thing with FFmpeg: probing, segmenting, transcoding, packaging, checksumming, and delivery are separate steps.
Quantum workloads are similar. The part that uses quantum hardware or quantum-inspired tooling is usually one stage in a pipeline. The rest is still conventional compute.
That means you should avoid asking, can quantum replace this workload? Ask which stage benefits from quantum execution, quantum simulation, or quantum-adjacent optimization.
The real interface is job orchestration
If you reduce the integration to an SDK call, you hide the operational problem. Production systems need job IDs, retry semantics, timeout policies, access controls, payment records, worker reputation, and audit logs.
Practical rule: Do not integrate a quantum backend until your system can describe work as portable jobs with explicit inputs, outputs, constraints, and settlement rules.
That rule matters because quantum capacity is not just another endpoint. It may be scarce, delayed, or expensive. Your control plane needs to decide when the job should run there, when it should fall back, and when the user should be told that the job is not suitable.
Where quantum computing inc fits in a decentralized compute marketplace

A decentralized compute marketplace already deals with heterogeneous supply. Some nodes are strong at AI inference. Some are better for FFmpeg transcoding. Some are cheap but slow. Some are trusted for private workloads. Quantum computing inc should be treated as another specialized supply class, not as a separate universe.
The practical design is a router that can classify jobs, match them to execution backends, and preserve enough context for validation and payment.
Treat quantum jobs as specialized backends
The marketplace should not pretend every worker can execute every job. That creates bad UX and worse accounting. Instead, model backend capability explicitly.
| Backend class | Good fit | Poor fit | Operational concern |
|---|---|---|---|
| CPU workers | preprocessing, scripts, packaging | high-throughput model serving | predictable scheduling |
| GPU workers | AI inference, embeddings, vision | low-value batch glue | memory and utilization |
| Video workers | FFmpeg transcode, probes, packaging | sensitive private media without policy | codecs and artifact checks |
| Quantum backend | optimization experiments, sampling, simulation-adjacent tasks | generic web requests, normal inference | queue time and validation |
This table is intentionally boring. Boring is good. It forces the scheduler to ask what a backend is for.
Separate routing from execution
Routing should happen before execution. Execution should not decide whether the job belongs on a quantum backend. That decision belongs in the control plane because it needs user intent, budget, policy, and workload classification.
For adjacent reading from our network: teams building local coordination systems face a similar routing-versus-execution problem in coupon and access workflows, which is discussed in coupon codes for local networks.
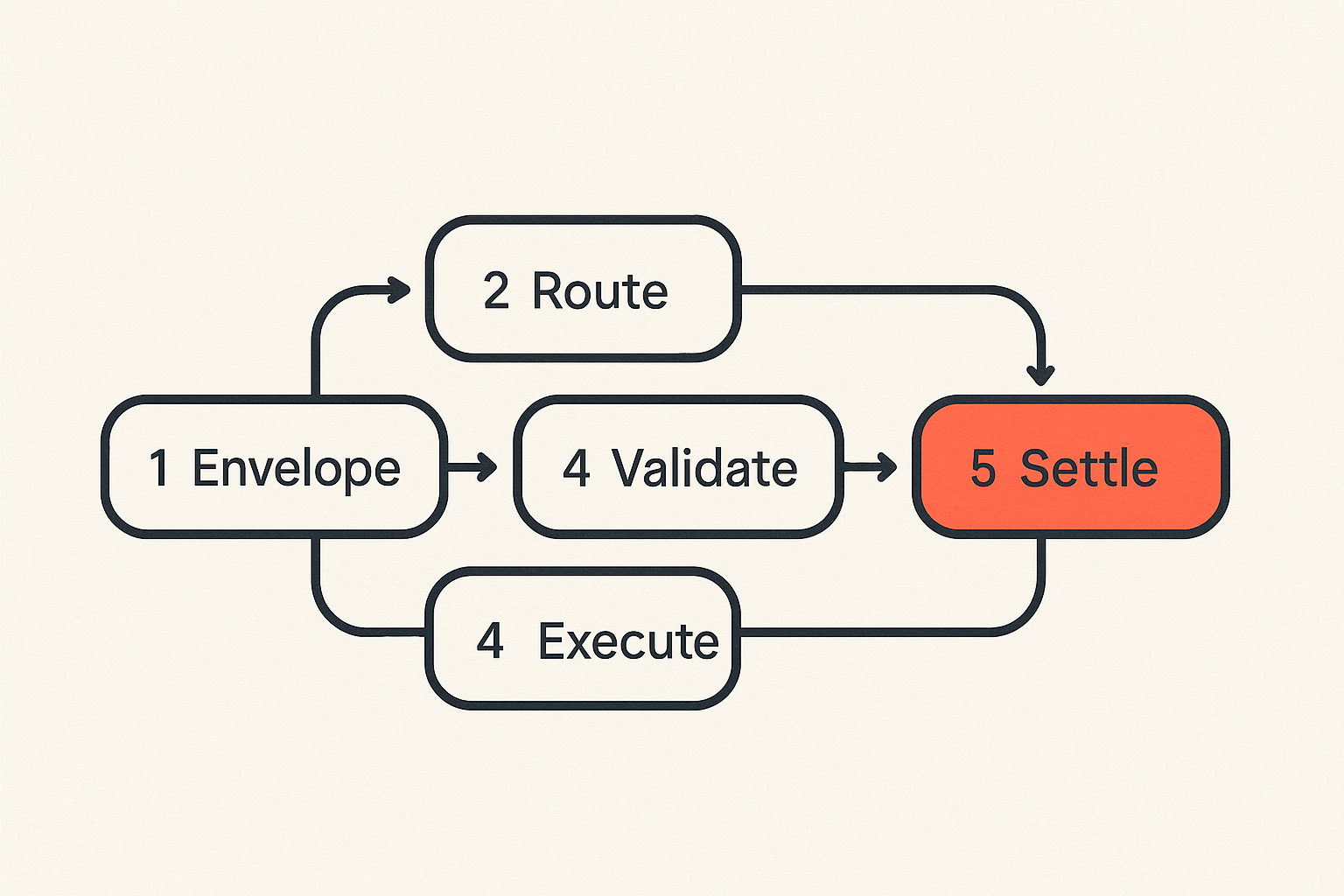
A clean split looks like this:
- The API accepts a job request.
- The classifier assigns execution class and constraints.
- The router chooses candidate backends.
- The executor runs the job.
- The validator checks outputs.
- The settlement layer pays the right party.
That changes the conversation. You are no longer asking whether quantum is magic. You are asking whether your router can make an explicit decision with a clear fallback.
The workload split between classical AI video and quantum
Most useful systems will be hybrid. That is not a compromise. It is the default architecture.
The classical side prepares data, runs normal transforms, stores artifacts, and handles user-facing latency. The quantum or quantum-adjacent side handles a narrow step where a specialized method may be useful. The postprocessing layer turns results back into something the rest of the system can consume.
What stays classical
A lot stays classical:
- API authentication
- input validation
- file storage
- media probing
- model selection
- prompt construction
- embeddings storage
- result formatting
- billing records
- support logs
For video infrastructure engineers, the pattern is familiar. You do not send a raw business workflow into FFmpeg and expect it to understand product rules. You create a command, constrain it, execute it, and validate artifacts.
Quantum workflows deserve the same discipline.
What becomes quantum-adjacent
Quantum-adjacent does not always mean direct quantum hardware execution. It may mean simulation, optimization, sampling, or vendor-specific methods that resemble quantum workflows.
Good candidates tend to have these traits:
- The problem can be isolated from the rest of the pipeline.
- Inputs can be represented compactly.
- Output quality can be scored or compared.
- Latency tolerance exists.
- Fallback methods are available.
Practical rule: If you cannot define the input shape and success criteria in one job envelope, the workload is not ready for quantum routing.
The useful mental model is not cloud versus quantum. It is general compute versus specialized execution under constraints.
The control plane you need before a quantum computing inc integration
Before integrating quantum computing inc or any similar specialized provider, build the control plane you wish you had when normal compute failed.
The control plane is where identity, policy, budget, queue state, and observability meet. It is also where most production failures become visible.
Identity policy and job envelopes
Every job needs an identity story. Who submitted it? Which DID or account owns it? Which worker can see it? Which backend is allowed to process it? Which payment rail funds it?
A job envelope should carry enough context to answer those questions without relying on tribal knowledge inside application code.
At minimum, include:
- job ID
- requester identity
- execution class
- input references
- output destination
- max budget
- timeout
- privacy policy
- validation mode
- payment intent
Builders exploring CLI-first decentralized execution can use the c0mpute docs as a reference point for how identity, workers, jobs, health checks, and network operations fit together in a compute workflow.
Queues retries and idempotency
What breaks in practice is not the first successful demo. It is the second request after a timeout.
If a user submits a quantum-adjacent job and the backend queues it for longer than expected, what happens? Does the marketplace cancel? Retry? Charge twice? Route to a classical fallback? Keep both and compare results?
You need idempotency keys and state transitions.
A simple state model:
created -> accepted -> routed -> queued -> running -> validating -> settled
| | | |
v v v v
rejected expired failed disputed
The point is not that this is the perfect state machine. The point is that there is a state machine. Without it, support becomes the state machine.
Practical rule: Retrying execution without idempotent settlement is how marketplaces accidentally pay twice or bill for work nobody can verify.
Data movement and trust boundaries
Quantum integrations are often discussed as algorithms. Operators should start with data boundaries.
Where is the input prepared? Where is it stored? Which provider sees it? Can it be reconstructed from a compact representation? Is the output sensitive? Can logs leak problem structure?
These questions matter more in decentralized systems because workers may be independent participants rather than machines inside one cloud account.
Input preparation and leakage risk
The safest pattern is to preprocess inputs into the minimum representation needed for the specialized backend. Do not ship raw customer data if a reduced matrix, graph, parameter set, or compiled circuit is enough.
For AI and video builders, this is similar to not sending full user history to an inference endpoint when a short prompt or embedding reference is enough. Keep sensitive context close to the requester or trusted worker, then send only the task-specific representation onward.
For adjacent reading from our network: privacy teams dealing with encrypted messaging discounts run into a related metadata problem, where the coupon flow can expose more than the content itself; see coupon codes for encrypted messaging apps.
Output verification and audit trails
Quantum outputs may be probabilistic, approximate, or dependent on run parameters. Your audit trail should capture more than final output.
Capture:
- backend selected
- submission timestamp
- queue duration
- run parameters
- random seeds where applicable
- versioned solver or SDK reference
- raw output artifact
- postprocessing version
- validation score
This is not academic paperwork. It is how you debug disputes.
If a buyer pays for a result and says it is wrong, you need enough context to decide whether the worker failed, the backend behaved within expected tolerance, the input was malformed, or the validation rule was weak.
Payments settlement and access control for quantum jobs
Quantum jobs make payments awkward because pricing may depend on backend class, queue priority, run count, shots, simulation size, or vendor policy. A flat job price may work for demos. It usually breaks when usage becomes variable.
The mistake teams make is treating price discovery as the whole payments problem. It is only the first half. The second half is settlement under uncertainty.
Price discovery is not the only pricing problem
A marketplace needs to answer several payment questions before execution:
- What is the maximum the requester is willing to spend?
- Is the price fixed, estimated, or metered?
- Who eats the cost of failed execution?
- Does validation happen before settlement?
- Can the requester cancel while queued?
- Is there an escrow or authorization hold?
For quantum-adjacent workloads, the safest default is budget-capped execution. The requester authorizes up to a maximum. The router selects a backend within that cap. Settlement occurs after validation or after an agreed terminal state.
DID-based payment flows
DID-based payment flows help because they bind identity, authorization, and settlement records to a job without forcing every worker into the same account system.
A practical flow:
- Requester signs a job envelope.
- Marketplace checks policy and budget.
- Router assigns execution candidates.
- Worker or backend accepts the assignment.
- Payment intent is locked or authorized.
- Output is submitted with proof metadata.
- Validator accepts, rejects, or disputes.
- Settlement releases payment according to state.
This is also where terms matter. For production marketplaces, define who owns failed-run cost and when a queued job becomes cancelable. Otherwise, every edge case becomes a manual negotiation.
Observability for hybrid quantum workflows
Observability is where hybrid compute stops being a diagram and starts being an operating system.
A normal dashboard that shows successful requests is not enough. You need to understand where time went, where money went, and where trust changed hands.
Metrics that matter
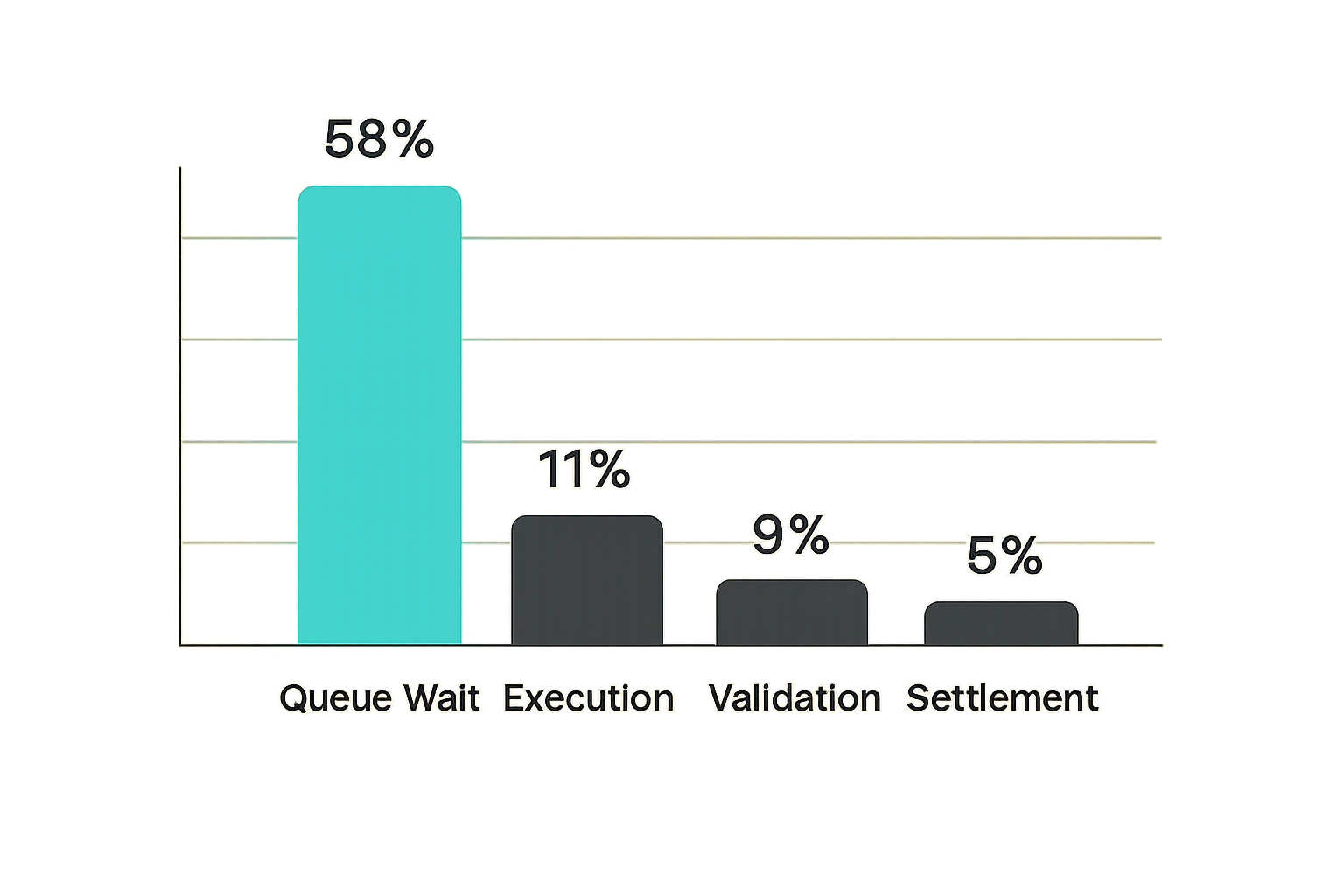
Track metrics by execution class, not just globally. If you mix CPU, GPU, video, and quantum-adjacent jobs in one success rate, you hide the only information operators need.
Useful metrics include:
- route decision count by class
- queue wait time
- execution duration
- validation failure rate
- retry count
- cancellation rate
- budget cap hit rate
- settlement delay
- dispute count
A useful dashboard separates stages. For example, a long total duration is not actionable. A long queue duration on one backend class is actionable.
Logs need correlation not volume
More logs do not solve orchestration bugs. Correlated logs do.
Use one job ID across API, router, executor, validator, and settlement. Store backend-specific IDs as child references. If the quantum provider returns a run ID, keep it, but do not make it your primary system ID.
Good log shape:
job_id: job_7k2
requester: did:example:alice
class: quantum_adjacent
route: provider_x.priority_low
state: validating
budget_cap: 25.00
backend_run_id: qrun_93a
validator: score_threshold_v2
What fails is scattered telemetry: API logs in one place, provider IDs in another, settlement events in a wallet indexer, and user support in chat. Nobody can reconstruct the job.
Implementation workflow for builders
The practical question is how to start without overbuilding. You do not need a full quantum marketplace on day one. You need a controlled integration path that proves the orchestration model before you expose it broadly.
Start with the smallest workflow that exercises routing, execution, validation, and settlement.
A practical integration sequence
- Define one narrow quantum-adjacent job type.
- Create a versioned job envelope for that type.
- Build a local mock executor that returns deterministic fixtures.
- Add a provider adapter behind the same executor interface.
- Implement timeout, cancellation, and idempotency keys.
- Add validation rules and store raw artifacts.
- Add budget caps and settlement states.
- Expose the workflow through CLI before building a UI.
- Run shadow jobs against classical fallback methods.
- Promote only after support can debug a failed job from one ID.
That sequence is intentionally conservative. It prevents the common failure where a team builds a polished UI around an execution path that cannot be retried, audited, or priced.
For background on adjacent vendor-specific thinking, our earlier guide to IBM quantum computing for decentralized compute builders covers similar routing and validation concerns from a different provider angle.
Minimal job envelope example
Keep the first envelope boring and explicit.
job_id: job_7k2
kind: optimization_sample
version: 1
requester_did: did:example:alice
execution_class: quantum_adjacent
input:
uri: ipfs://bafy-input
hash: sha256:abc123
constraints:
max_budget_usd: 25
timeout_seconds: 1800
allow_fallback: true
privacy: reduced_input_only
validation:
mode: compare_score
threshold: 0.92
payment:
intent_id: pay_44x
settle_on: validated
outputs:
destination: ipfs://bafy-output-prefix
This envelope does not solve every case. It gives every component the same contract. The router can read it. The executor can run it. The validator can score it. The payment layer can settle it.
What breaks when teams implement quantum computing inc badly
Bad implementations rarely fail because the math is not interesting. They fail because the system cannot explain what happened.
In production, users do not ask whether the quantum backend was conceptually promising. They ask why a job took 47 minutes, why they were charged, why the output changed, or why retrying produced a different result.
Failure modes in production
Common failure modes:
- SDK-first integration with no job state model
- provider run IDs used as primary marketplace IDs
- no classical fallback for unsuitable workloads
- retries that create duplicate charges
- outputs stored without run parameters
- privacy policy ignored during preprocessing
- all backend metrics merged into one dashboard
- validation treated as a manual review step
- pricing exposed before cancellation rules exist
For adjacent reading from our network: remote teams run into the same operational trap when a visible interface hides permission, recovery, and support rules, as shown in Samsung TV remote workflows for remote teams.
What works and what fails
| Area | What works | What fails |
|---|---|---|
| Routing | classify jobs before execution | let provider adapter decide policy |
| Identity | signed job envelopes | API keys passed through scripts |
| Payment | budget caps and settlement states | charge on submit with no validation |
| Validation | score outputs with stored artifacts | trust final response text |
| Observability | one job ID across all stages | separate logs per component |
| UX | CLI-first workflow with clear states | glossy dashboard hiding queue state |
Practical rule: If support cannot answer what happened to a job from one ID, the architecture is not production-ready.
This is the operator test. Not benchmark charts. Not vendor decks. One ID, one trace, one settlement record.
Product fit c0mpute.com and hybrid compute routing
c0mpute.com is built around a simple idea: decentralized compute should be usable by technical builders without pretending the UI is the system. The interesting work is in job routing, worker capability, identity, payment, and validation.
That maps naturally to hybrid compute. AI inference, FFmpeg transcoding, and quantum-adjacent workloads are different execution classes, but they need many of the same control-plane primitives.
Where decentralized compute helps
Decentralized compute helps when workloads can be described, routed, verified, and paid for as jobs. That includes many AI inference tasks, video processing pipelines, and batch-style transformations.
The value is not that every worker can do everything. The value is that the network can expose diverse capability behind one operational model.
For builders who want a CLI-first network for transcoding, inference, DID payments, and worker operations, c0mpute.com is the product surface for that architecture.
Where quantum remains external
Quantum execution may remain external for a long time. That is fine. The marketplace does not need to own every backend to route work intelligently.
The right abstraction is an adapter model:
- native workers for normal decentralized compute
- trusted adapters for specialized providers
- validation layers that compare outputs
- payment states that reflect actual completion
- policy controls that decide where data may go
This avoids the worst version of quantum integration: a hardcoded provider path sitting outside the rest of the compute network.
Closing checklist for quantum computing inc decisions
If you are evaluating quantum computing inc in 2026, do it as an architecture review, not a procurement exercise. The provider matters, but the workflow around the provider matters more.
The practical question is whether your system can route specialized work without losing control of identity, cost, data, validation, and support.
Questions to answer before building
Ask these before you write the adapter:
- What exact job type are we supporting first?
- What input representation is allowed?
- What makes the output acceptable?
- What is the classical fallback?
- Who pays for failed or canceled jobs?
- What is the maximum queue time?
- Which logs and artifacts are required for disputes?
- Can a user reproduce or audit the result?
- Can support debug the job from one ID?
If the answers are vague, the integration is not ready. Keep it in research mode.
The operating principle
Quantum computing inc should be treated as a specialized execution option inside a broader compute architecture. Not a magic endpoint. Not a separate product silo. Not a reason to bypass routing, settlement, or validation.
Build the boring parts first. Job envelopes. State machines. Budget caps. Correlated logs. Fallbacks. Audit trails. Then add the specialized backend.
That is how quantum computing inc becomes a usable workflow instead of a fragile demo.
Try c0mpute.com
You are writing for technical builders interested in decentralized compute, AI inference, FFmpeg transcoding, and DID-based payments. Try c0mpute.com