IBM quantum computing creates a planning problem before it creates a performance problem.
A team sees quantum access, opens a notebook, runs a circuit, and assumes the next step is integration. Then the real system shows up: queue time, simulator fallbacks, circuit transpilation, result validation, payment boundaries, retry logic, and users who expect a job to finish with an explainable status.
Teams think the problem is access to a quantum computer. The real problem is building a workflow that can decide when quantum hardware is useful, route work safely, prove what happened, and settle value across multiple compute backends.
That changes the conversation. For web3 developers, AI infrastructure builders, video engineers, and CLI-first operators, ibm quantum computing is not a replacement for GPUs, CPUs, or FFmpeg workers. It is another specialized execution target. The practical question is how to plug that target into a compute marketplace without turning every job into an experiment.
Table of contents
- Why IBM quantum computing is an orchestration problem
- What IBM quantum computing changes in 2026 compute planning
- Where quantum fits in a decentralized compute marketplace
- A reference workflow for quantum-adjacent jobs
- The scheduler contract: route, price, and verify
- Data boundaries, identity, and payments
- What works and what fails in implementation
- Observability and operational metrics
- Common failure modes when teams ship quantum workflows
- How c0mpute.com fits the architecture
- Closing checklist for IBM quantum computing builders
Why IBM quantum computing is an orchestration problem
Not a faster GPU
The mistake teams make is treating ibm quantum computing like a new accelerator class. They put it mentally beside Nvidia GPUs, CPU clusters, or video transcode workers. That model breaks quickly.
A GPU takes a tensor workload and returns a tensor result. A transcode worker takes an input media file and returns an output file. A quantum backend takes a circuit, runs repeated shots under hardware constraints, and returns measurement distributions that usually require classical post-processing. The value is not raw throughput in the normal cloud sense. The value is specialized sampling, optimization research, simulation, and algorithm exploration.
For production architecture, that means quantum is rarely the whole workload. It is one stage in a larger pipeline. The surrounding system still needs object storage, job manifests, API authentication, scheduling, logs, retries, result normalization, payment, and support tooling.
Practical rule: Do not route a job to quantum hardware until you can explain what classical work happens before it, what classical work happens after it, and how the final result will be judged.
The useful unit is a routed job
A useful way to think about it is the routed job. The user does not buy quantum. The user submits a job with constraints: desired algorithm, input size, acceptable latency, budget, reproducibility level, and output format.
The scheduler then decides whether the job should run on a simulator, a classical worker, a quantum backend, or a hybrid chain. This is the same architecture instinct that works in decentralized compute. A marketplace should not expose every worker detail to every user. It should expose enough capability metadata for a rational route.
Related reading from our network: teams building local AI agent workflows face similar routing and credential boundaries in Mac tools for AI agent builders, even though their execution targets are different.
What IBM quantum computing changes in 2026 compute planning
Cloud access is not the same as production capacity
IBM has made quantum systems accessible through cloud workflows, but access does not remove production constraints. Queue time, backend availability, calibration windows, shot limits, circuit depth, transpilation choices, and account permissions still matter.
In a prototype, a developer can wait and inspect results manually. In production, a marketplace or API has to tell a user what state the job is in. Queued is different from running. Running is different from post-processing. Post-processing is different from verified. Failed with fallback is different from failed without charge.
That state model is the difference between a demo and an operator-grade system.
Hybrid workloads become normal
Most practical quantum workflows are hybrid. Classical machines prepare inputs, optimize parameters, test baselines, run simulations, and validate outputs. Quantum hardware may be invoked for one specific sampling or optimization step.
For AI builders, this matters because the natural comparison is not quantum versus AI inference. It is quantum plus classical orchestration beside AI inference. For video infrastructure engineers, the same principle is familiar: FFmpeg does not exist alone. It sits behind queues, storage, probes, presets, progress updates, and delivery logic.
The practical question is not whether ibm quantum computing is powerful in the abstract. The question is whether a specific stage in your workflow benefits enough to justify queue time, uncertainty, and integration cost.
Where quantum fits in a decentralized compute marketplace
The marketplace does not sell magic
A decentralized compute marketplace should sell execution with clear constraints. That applies to AI inference, FFmpeg transcoding, and quantum-adjacent jobs.
If a marketplace claims that every problem becomes faster because quantum exists, it is selling confusion. The better model is capability matching. Workers advertise what they can do. Schedulers enforce policy. Users submit jobs. Results are validated. Payments settle according to the contract.
A quantum provider may not be a decentralized worker in the same way a community GPU node is. It may be an external backend accessed through a controlled adapter. That is fine. Architecture should describe reality, not pretend every backend has the same trust model.
The broker owns policy, not science
The broker should not decide scientific truth. It should decide operational policy.
Examples:
- Is the user allowed to request hardware execution?
- Is the budget high enough for the expected route?
- Should a simulator run first as a sanity check?
- What happens when the quantum queue exceeds the maximum wait?
- Which result fields are required before payment settlement?
- Does the output include enough metadata to reproduce or challenge the run?
This is where web3 infrastructure has useful instincts. Identity, escrow, signed manifests, reputation, and settlement are not cosmetic. They are how unknown parties coordinate work without pretending trust is free.
A reference workflow for quantum-adjacent jobs
Step sequence for a real job
A production quantum workflow should look boring. Boring is good. Boring means support can debug it at 3 a.m.
- The client submits a job manifest with algorithm type, input reference, budget, deadline, and acceptable backends.
- The scheduler validates the manifest and runs a classical precheck or simulator pass.
- The router selects a backend: classical, simulator, quantum hardware, or hybrid.
- The executor submits the circuit or task and records external job identifiers.
- The post-processor normalizes results, attaches provenance, and runs validation checks.
- The settlement layer releases payment, refunds, or partial payment based on the agreed state.
Here is a simple manifest shape that avoids pretending quantum jobs are just RPC calls:
job_type: quantum_optimization
algorithm: qaoa_candidate
input_uri: ipfs://input-bundle
max_wait_seconds: 1800
budget_units: 250
fallback: simulator
validation:
require_baseline: true
min_result_fields:
- measurement_counts
- backend_name
- shot_count
- transpiler_seed
settlement:
pay_on: verified
refund_on: expired
The exact fields will vary, but the principle holds: the manifest describes intent, limits, fallback, validation, and settlement. Without those fields, the operator has to infer policy during an incident.
Implementation notes for CLI-first teams
CLI-first builders should resist the urge to hide everything behind a web UI. A UI can help later. The first useful interface is a command that produces a manifest, submits it, streams state changes, and prints a final receipt.
Example shape:
compute quantum submit ./job.yaml
compute job watch job_7f3a
compute job receipt job_7f3a --format yaml
The receipt matters. It should include route, backend, timestamps, cost, validation status, and artifact references. This gives developers something they can test in CI, paste into an issue, or attach to a dispute.
For c0mpute-specific CLI patterns around workers, jobs, identity, and health checks, the c0mpute docs are the natural place to align job manifests with the rest of the network model.
The scheduler contract: route, price, and verify
Routing needs explicit capability metadata
Schedulers fail when capability is implicit. A quantum-capable route should advertise constraints in machine-readable form.
Useful metadata includes:
- backend family
- simulator or hardware
- maximum circuit width
- practical circuit depth limits
- supported algorithm templates
- expected queue behavior
- authentication scope
- result schema version
- validation mode
- settlement policy
This is not busywork. It prevents the scheduler from sending the wrong job to the wrong target and then asking support to reverse-engineer the failure.
Practical rule: If a route cannot describe its limits, it should not receive paid jobs.
Pricing needs fallback states
Quantum workflows need pricing that understands partial progress. A job might run a simulator successfully, then time out waiting for hardware. Another job might reach hardware, produce valid counts, but fail downstream validation. A third might be rerouted before any external cost is incurred.
A simple comparison helps:
| State | User expectation | Operator action | Settlement behavior |
|---|---|---|---|
| Accepted | Job is valid and queued | Reserve budget | Hold funds |
| Simulated | Baseline completed | Attach baseline artifact | Partial charge or continue |
| Hardware queued | External backend wait | Stream state updates | Continue hold |
| Hardware complete | Raw result received | Normalize and validate | Not final yet |
| Verified | Output meets contract | Release receipt | Pay worker or adapter |
| Expired | Deadline exceeded | Stop route | Refund or partial refund |
| Invalid | Manifest or output failed | Return reason | No charge or dispute path |
The mistake teams make is charging on submission. That creates support debt. Charge on meaningful states, and make those states visible.
Data boundaries, identity, and payments
Keep secrets out of quantum tasks
Quantum tasks should not carry unnecessary secrets. Most workloads should send circuits, parameters, and references to prepared inputs, not raw customer data or private keys.
This sounds obvious until a team builds a quick adapter that forwards the full job context to an external backend. What breaks in practice is not only confidentiality. It is auditability. Nobody can later explain which fields left the network, which identity authorized it, and whether the external task was necessary.
The better pattern is scoped transformation:
- prepare a minimal execution bundle
- sign the bundle hash
- submit only the required fields
- store external identifiers separately
- bind the returned result to the original manifest
- expose redacted logs by default
Related reading from our network: secure messaging teams wrestle with similar metadata and key-boundary problems in end to end encryption messaging architecture, and the lesson transfers cleanly to compute workflows.
Bind results to identity and settlement
A decentralized compute marketplace needs more than a result file. It needs a chain of custody.
At minimum, bind these items together:
- requester identity
- job manifest hash
- selected route
- worker or adapter identity
- external backend job ID where applicable
- output artifact hash
- validation status
- payment status
This does not require turning every event into a public on-chain write. Many systems should keep operational logs off-chain and settle only the necessary state. The point is that identity, result, and payment cannot be three disconnected systems.
Practical rule: A result that cannot be linked to a manifest, route, and settlement decision is not a production result. It is an artifact.
What works and what fails in implementation
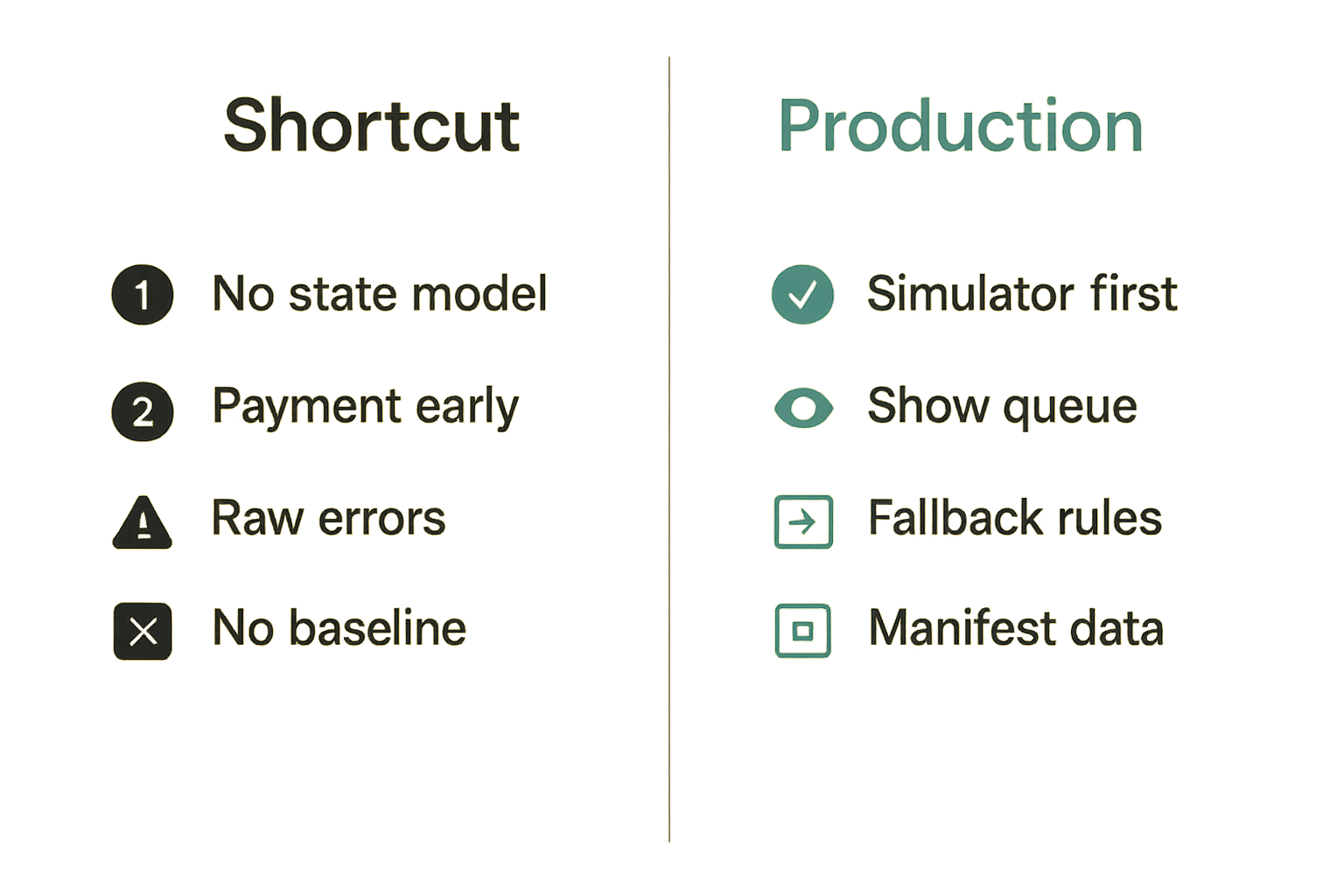
What works
What works is a layered design that treats ibm quantum computing as one backend among several, with stricter policy around validation and state.
Good implementations usually share a few traits:
- They run simulator baselines before hardware when possible.
- They expose queue state instead of hiding latency.
- They define refund and fallback behavior before launch.
- They keep manifests small and explicit.
- They store enough provenance to reproduce the route decision.
- They separate user-facing status from provider-specific errors.
- They test adapters with fake backends and forced timeouts.
That last point is underrated. If you cannot simulate a stuck queue, expired credential, malformed result, duplicate callback, or partial failure, you do not have a production integration. You have optimism with a webhook.
What fails
What fails is the notebook-to-platform shortcut.
A notebook can demonstrate an algorithm. It cannot define a marketplace contract. It will not answer who pays when the backend is unavailable, which version of the transpiler was used, whether a simulator fallback is acceptable, or how to handle duplicate result events.
Common bad patterns:
- one API endpoint called runQuantum with no state model
- payment captured before route selection
- raw provider errors shown to users
- no baseline comparison
- no output schema versioning
- no replay protection for callbacks
- no dispute path for ambiguous results
The practical question is not whether the first demo worked. The question is whether the hundredth job fails in a way your system can explain.
Observability and operational metrics
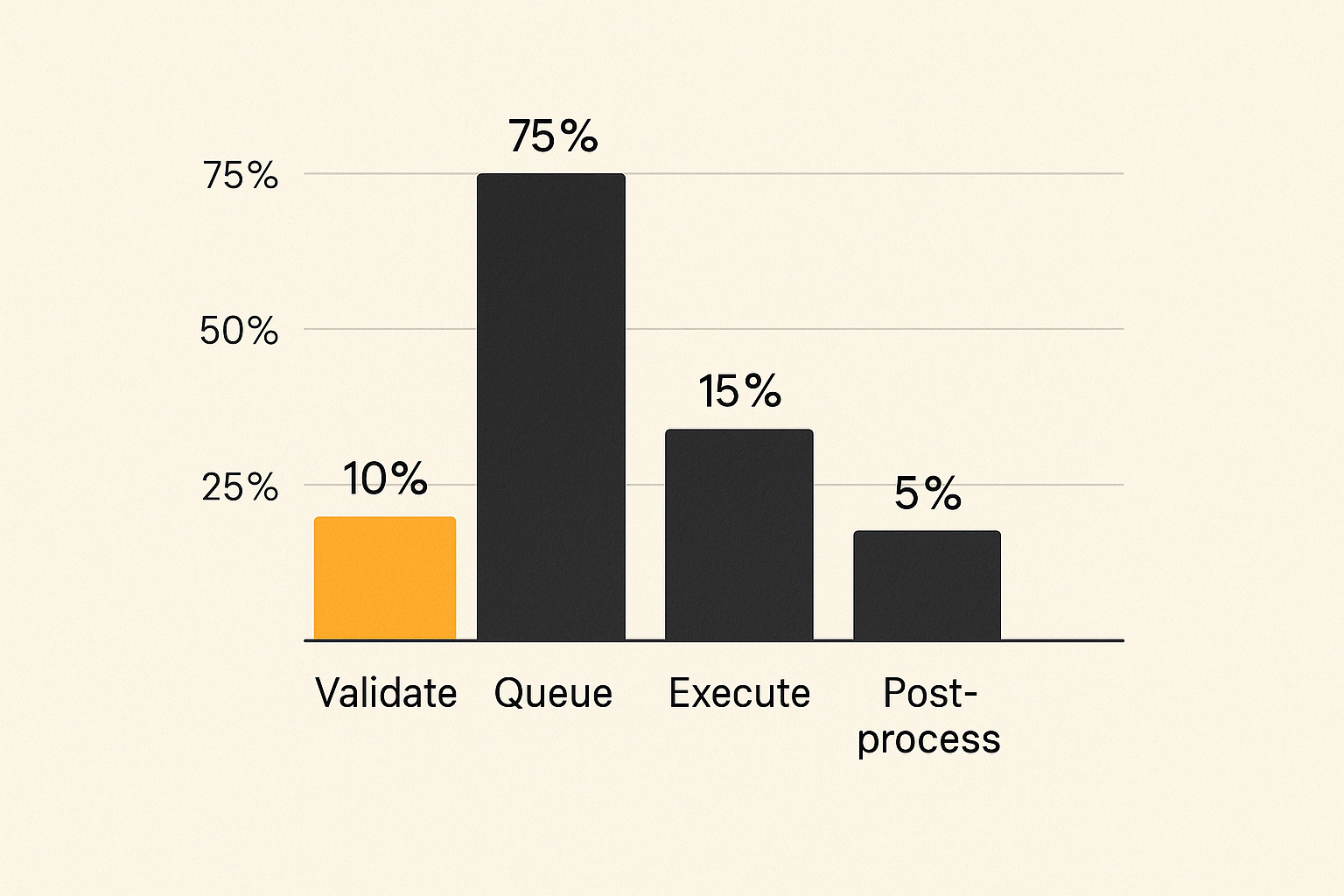
Track the queue, not just the execution
Quantum observability starts before execution. Queue time is part of the user experience and part of the cost model.
Track at least:
- manifest validation latency
- scheduler decision latency
- simulator runtime
- external queue time
- hardware execution time
- result normalization time
- validation duration
- total time to receipt
- fallback rate
- refund rate
If you only measure execution time, you will optimize the wrong thing. In many workflows, the user experiences waiting, uncertainty, and state transitions more than raw execution.
The c0mpute status page is a useful reminder that distributed compute systems need visible operational state; quantum adapters should be held to the same standard rather than hidden behind vague pending labels.
Make validation a first-class metric
Validation is not a footnote. It is where a quantum-adjacent workflow becomes useful or becomes theater.
Validation may include:
- comparing against a classical baseline
- checking output schema completeness
- confirming shot count and backend metadata
- detecting impossible or malformed distributions
- verifying artifact hashes
- ensuring result freshness
- checking that fallback behavior matched policy
The metric to watch is not just success rate. Watch verified success rate. Also watch ambiguous completion rate: jobs that technically returned something but did not satisfy the contract. Ambiguous completion is where support tickets and payment disputes grow.
Related reading from our network: hiring and productivity systems have a different domain, but the same workflow truth appears in software engineer jobs workflow design: unclear ownership and unclear states create operational drag.
Common failure modes when teams ship quantum workflows
Failure mode: quantum as a checkbox
The most common failure is adding quantum as a brand checkbox. The product says it supports ibm quantum computing, but the workflow does not explain when or why it uses it.
Users eventually ask basic questions:
- Did my job actually run on hardware?
- Why did it take this long?
- What was the baseline?
- What did I pay for?
- Can I reproduce the result?
- What happens if I disagree with the output?
If the system cannot answer, the quantum feature becomes a trust liability.
A better product posture is narrower and more honest. Support specific job classes. Publish constraints. Show route decisions. Offer simulator-first mode. Make hardware execution opt-in for jobs where it matters.
Failure mode: unverifiable outputs
The second failure is returning outputs without context. A histogram or optimized parameter set may be interesting, but it is not enough.
A verifiable output should include metadata:
result:
schema: quantum_result_v1
job_id: job_7f3a
manifest_hash: bafy_manifest
route: simulator_then_hardware
backend: ibm_backend_alias
shots: 4096
validation: passed
baseline_artifact: ipfs://baseline
output_artifact: ipfs://result
settlement: released
Avoid exposing provider internals that users cannot act on, but keep enough detail to make the result inspectable. The goal is not maximal disclosure. The goal is operational proof.
How c0mpute.com fits the architecture
Use decentralized compute for the surrounding work
Most of the work around ibm quantum computing is not quantum work. It is preparation, simulation, validation, transformation, storage, and settlement. That is exactly where decentralized compute can be useful.
In a c0mpute-style architecture, FFmpeg workers can handle media pipelines, inference workers can handle AI tasks, and specialized adapters can connect to external execution targets. Quantum belongs in that same orchestration conversation: a constrained backend selected by policy, not a magic side door.
For builders exploring decentralized compute primitives, the main c0mpute.com network model is CLI-first and organized around practical modules like transcode, infernet, and DID-based payments. That makes it a better mental fit for routed workloads than a dashboard-only abstraction.
Use quantum only where it earns its place
The product-fit answer is intentionally narrow. c0mpute.com should not pretend quantum replaces GPUs or transcode nodes. It should help builders structure jobs so specialized execution targets can be plugged in without corrupting the rest of the workflow.
That means:
- manifests over ad hoc API calls
- route policy over hype
- receipts over screenshots
- validation over vague success
- payment states over blind charges
- adapters over hardcoded provider logic
If a quantum stage creates value, route to it. If a simulator or classical worker is better, use that. A marketplace earns trust by making the correct route legible.
Closing checklist for IBM quantum computing builders
Questions to answer before integration
Before adding ibm quantum computing to a compute product, answer these questions in writing:
- Which job class is supported first?
- What is the classical baseline?
- When is hardware allowed?
- What is the maximum wait time?
- What fields are required in the result?
- How are retries handled?
- What happens on duplicate callbacks?
- When does the user pay?
- What gets refunded?
- What receipt proves the route?
- Who owns support when the external backend fails?
If those answers are unclear, do not start with UI. Start with the manifest and the state machine.
The operator mindset
IBM quantum computing is valuable when it is integrated as a disciplined execution target. It becomes fragile when teams sell it as an abstract capability without workflow ownership.
The operator mindset is simple: define the job, constrain the route, observe every state, validate the output, and settle payment only when the contract is satisfied. That is how quantum-adjacent work can fit into decentralized compute without turning the network into a science fair.
The closing point is the same as the opening one: ibm quantum computing is not just a backend decision. It is an architecture decision.
Try c0mpute.com
c0mpute.com is for technical builders interested in decentralized compute, AI inference, FFmpeg transcoding, and DID-based payments. Try c0mpute.com