IBM quantum computing sounds like a hardware conversation until you try to put it behind an API, price it in a marketplace, and support failed jobs at 2 a.m.
Teams think the problem is access to a quantum machine. The real problem is workflow control: job routing, queue latency, reproducibility, cost boundaries, credentials, validation, and settlement.
That changes the conversation. For web3 developers, AI infrastructure builders, FFmpeg pipeline operators, and CLI-first engineers, IBM quantum computing is not a magic accelerator you bolt onto a GPU cluster. It is another execution backend with unusual constraints and a very different failure model.
The practical question is not whether quantum will replace classical compute in 2026. It will not. The practical question is where a decentralized compute marketplace should place quantum jobs in its architecture so builders can experiment without breaking billing, trust, or operations.
Table of contents
- IBM quantum computing is a workflow decision, not a GPU replacement
- The workload boundary between classical and quantum compute
- A practical IBM quantum computing architecture for marketplaces
- Marketplace implications for pricing, identity, and reputation
- Developer workflow for CLI-first quantum jobs
- What works with IBM quantum computing in 2026
- What fails when teams implement quantum badly
- Payments, settlement, and support for quantum workloads
- Operating IBM quantum computing in production-adjacent systems
- Where c0mpute.com fits in a quantum-ready compute marketplace
IBM quantum computing is a workflow decision, not a GPU replacement

The mistake teams make is comparing IBM quantum computing to GPUs, CPUs, or video transcode workers as if the only question is speed. That comparison is too shallow.
A useful way to think about it is this: GPUs are capacity you schedule for known workloads. Quantum backends are specialized instruments you access through constrained workflows. They can be valuable, but they do not behave like elastic commodity compute.
Not a general accelerator
Most marketplace workloads are still classical. AI inference, embeddings, model fine-tuning, FFmpeg transcoding, thumbnail generation, indexing, and data transformation all have clear CPU or GPU execution paths. You can benchmark them, retry them, shard them, and price them.
IBM quantum computing belongs in a different lane. It is relevant when the workload is expressed as a quantum circuit, a hybrid optimization loop, a simulation experiment, or a research task that needs quantum hardware access or a quantum simulator.
Practical rule: If the job cannot describe why it needs a quantum circuit, route it to classical compute.
This sounds obvious, but in product discussions it prevents waste. Do not add a quantum option to a marketplace checkout just because it is impressive. Add it when the job schema, runtime, and result format justify it.
Where quantum fits today
In 2026, quantum is most useful for experimentation, research workflows, algorithm development, and hybrid pipelines where classical code prepares inputs, submits quantum work, then analyzes output. That means the marketplace should not treat quantum as a worker pool identical to GPU inference.
The fit is closer to a provider-backed job type:
- user submits a circuit or high-level experiment manifest
- marketplace validates shape, limits, identity, and budget
- broker routes to a simulator or IBM quantum backend
- job waits in queue
- result returns as a signed artifact
- marketplace settles payment based on accepted completion rules
That is an architecture problem, not a landing page problem.
What changes the conversation
Once you treat quantum as a workflow, the hard questions become concrete:
- Who owns provider credentials?
- What happens when queue time exceeds user tolerance?
- How do you replay a job for validation?
- What result metadata is required for settlement?
- Is the marketplace selling access, completion, or a best-effort experiment?
Those questions matter more than the label on the compute resource.
The workload boundary between classical and quantum compute
The right boundary is simple: keep orchestration, validation, payments, and user experience classical. Use IBM quantum computing only for the quantum execution segment.
That boundary prevents the system from becoming mystical. A quantum job is still a job. It has inputs, state transitions, logs, artifacts, and a final status.
Classical orchestrators remain the control plane
Your marketplace control plane should remain ordinary software. Postgres, queues, object storage, signing keys, event streams, webhooks, and CLI commands still do the heavy lifting.
The orchestrator should decide:
- whether the job is eligible
- whether the budget is sufficient
- whether a simulator is more appropriate than hardware
- whether provider quotas allow submission
- whether the user can cancel before execution
- whether the result is complete enough for settlement
Quantum should not leak into every part of the stack. It should sit behind an adapter.
Related reading from our network: teams designing private collaboration systems face a similar separation between application workflow and sensitive key material in end to end encryption messaging architecture.
Quantum jobs are batch jobs with queue risk
What breaks in practice is latency expectation. Developers expect APIs to return quickly. Quantum hardware access often behaves more like a queued lab instrument than a low-latency RPC.
That affects UX and payments. A user should not submit a job and wonder whether it is stuck, waiting, executing, failed, or complete. Job state must be explicit.
Useful states include:
| State | Meaning | User action |
|---|---|---|
| accepted | Manifest is valid and budget is reserved | Wait or cancel |
| queued | Provider submission succeeded | Wait or cancel if policy allows |
| running | Provider started execution | Usually cannot cancel |
| artifact_pending | Execution finished, result is being normalized | Wait |
| complete | Artifact is available and settlement can finalize | Download result |
| failed_retryable | Provider or queue failure occurred | Retry or refund |
| failed_final | Job cannot complete under policy | Refund or dispute |
Treat results as artifacts
A quantum result should not be just a response body. Store it as an artifact with provenance.
At minimum, keep:
- submitted manifest hash
- normalized circuit or experiment representation
- provider name and backend class
- simulator versus hardware flag
- queue timestamps
- execution timestamps
- shot count or equivalent run parameter
- result payload
- logs and warnings
- signature from the marketplace or broker
Practical rule: If you cannot replay, inspect, or explain a result later, it is not ready for marketplace settlement.
This is especially important for decentralized systems. Users, workers, brokers, and payers may not all trust each other by default. Artifacts become the shared record.
A practical IBM quantum computing architecture for marketplaces
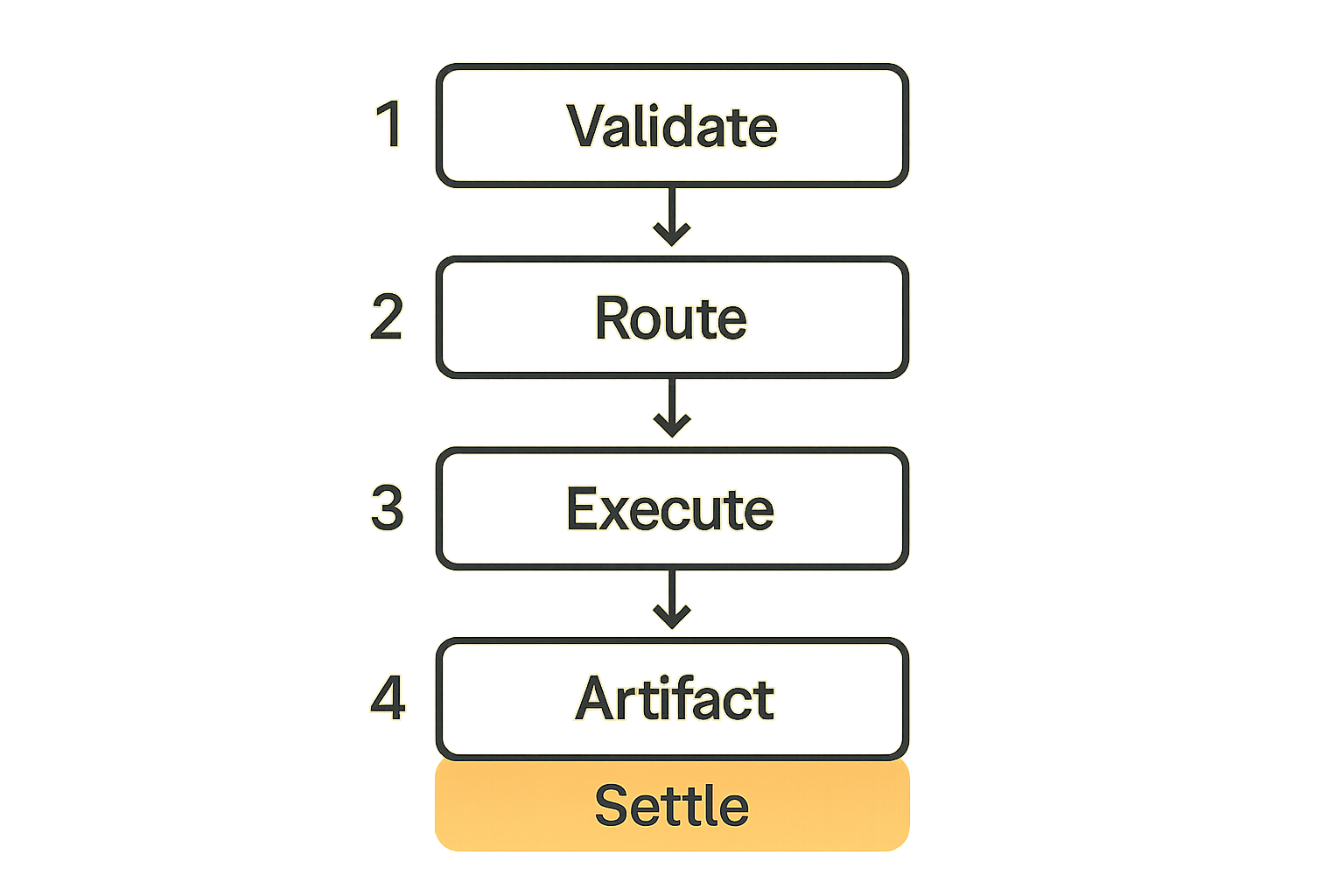
A marketplace does not need to become a quantum platform. It needs a clean execution lane that can submit, track, and validate quantum jobs without contaminating the rest of the system.
The pattern looks like this:
- Accept a typed job manifest.
- Validate budget, identity, schema, and limits.
- Route to simulator, IBM quantum backend, or rejection.
- Submit through a provider adapter.
- Track state transitions through events.
- Store result artifacts.
- Finalize payment or refund.
- Expose logs and artifacts through CLI and API.
Job intake and routing
Routing is where many teams overcomplicate the first version. You do not need a universal scheduler. You need a policy engine with boring rules.
Example routing inputs:
- requested backend class
- max queue time
- max spend
- simulator acceptable or not
- circuit size limits
- required result format
- user reputation or plan
- provider quota
- compliance or geographic constraints
A simple routing table can go far:
| Request type | Preferred route | Fallback | Reject when |
|---|---|---|---|
| learning experiment | simulator | low-priority hardware | manifest too large |
| research run | hardware queue | simulator if allowed | budget too low |
| hybrid optimizer | simulator for dry run, hardware for final | pause | loop exceeds limit |
| demo workload | simulator | none | user requests guarantee |
The important part is honesty. Do not silently downgrade hardware to simulation unless the manifest allows it.
Broker and provider adapter
The broker should isolate marketplace logic from provider-specific details. If IBM changes an SDK behavior, backend name, queue response, or result shape, the adapter changes. The job ledger should not.
Broker responsibilities:
- translate marketplace manifest into provider submission
- enforce timeout and cancellation policy
- redact or isolate provider credentials
- normalize provider states into marketplace states
- persist raw and normalized results
- emit signed completion events
This is the same pattern that works for other specialized execution backends. If you are already building CLI-first worker flows, the c0mpute docs are useful context for thinking about identity, workers, health checks, jobs, and operational commands across different compute modules.
Validation and replay
Validation does not always mean proving the quantum result is correct in the mathematical sense. It means proving the marketplace did what it promised.
For each job, you should be able to answer:
- Was the submitted manifest the one executed?
- Was the route allowed by policy?
- Was the backend simulator or hardware?
- Did the job finish inside the accepted policy window?
- Is the result artifact complete?
- Was settlement based on the correct state transition?
For deeper architectural context on this same topic, the prior c0mpute article on IBM quantum computing and decentralized compute architecture goes further into routing, validation, and hybrid job design.
Marketplace implications for pricing, identity, and reputation
Adding IBM quantum computing to a decentralized compute marketplace changes the commercial model. Not because every job becomes expensive, but because uncertainty becomes part of the product.
Classical compute pricing usually maps to duration, tokens, frames, bytes, or reserved hardware. Quantum access may include queue time, provider cost, shot count, backend class, retries, and experiment policy.
Pricing uncertain latency
The mistake teams make is pricing only execution time. Users experience total time: accepted to complete.
A more practical pricing model separates the components:
| Component | Why it exists | Billing treatment |
|---|---|---|
| validation | marketplace checks manifest and budget | usually free or tiny fee |
| reservation | funds held while queued | escrow, not revenue yet |
| provider execution | actual backend run | bill on accepted completion |
| artifact processing | normalization, storage, signing | included or small fee |
| retry | provider failure or user change | policy-dependent |
This gives support teams a clean explanation. The user did not pay because a spinner moved. The user paid because a specific completion condition was met.
DID identity and scoped access
Decentralized compute systems need identity boundaries. For quantum jobs, identity is not just login. It controls who can submit jobs, spend budget, access artifacts, and request reruns.
DID-based identity can help separate:
- user identity
- payer identity
- broker identity
- worker identity
- artifact signer identity
- support operator identity
The broker should not expose provider credentials to arbitrary workers. Workers should not be able to mutate settlement records. Support should not be able to alter artifacts without an audit trail.
Practical rule: Provider credentials belong behind the broker. Users submit intent; the marketplace controls execution policy.
Worker reputation for hybrid jobs
Quantum workflows often include classical pre-processing and post-processing. That means reputation still matters.
A hybrid job may involve:
- data preparation on a CPU worker
- parameter search on a GPU worker
- circuit submission through a quantum broker
- analysis on another classical worker
- artifact packaging by the marketplace
Reputation should attach to the part each actor controls. Do not blame a CPU worker for provider queue time. Do not reward a broker for a post-processing task it did not perform.
This granularity matters if the marketplace later uses reputation for routing or pricing.
Developer workflow for CLI-first quantum jobs
Developers do not want a vague quantum button. They want a contract they can script.
A CLI-first workflow should let a builder submit a job, inspect state, stream events, fetch artifacts, and reconcile payment without opening a dashboard.
The CLI contract
A good CLI contract is predictable:
- Create or reference identity.
- Validate the job locally.
- Estimate cost and policy constraints.
- Submit the job.
- Watch state transitions.
- Fetch artifact.
- Verify artifact hash and signature.
- Release, refund, or dispute payment based on state.
Example commands might look like this:
compute quantum validate job.yaml
compute quantum estimate job.yaml
compute quantum submit job.yaml --max-queue 2h --escrow did:example:payer
compute jobs watch jq_7f3a
compute artifacts get jq_7f3a --verify
compute payments status jq_7f3a
The exact command names matter less than the invariant: the developer can automate the workflow.
Example job manifest
The manifest should be boring and explicit. Avoid hiding policy in the UI.
kind: quantum.job
version: 1
name: portfolio-optimizer-test
identity: did:example:builder123
budget:
max_amount: 25.00
currency: USDC
escrow: required
execution:
provider: ibm
backend: hardware-or-simulator
simulator_allowed: true
max_queue_seconds: 7200
shots: 4096
inputs:
circuit_uri: ipfs://bafy-example-circuit
parameters_uri: ipfs://bafy-example-params
outputs:
format: normalized-json
include_raw_provider_result: true
settlement:
bill_on: complete
refund_on_timeout: true
This kind of manifest gives the router, broker, payer, and support team the same source of truth.
What the callback returns
Callbacks should carry state, not vague notifications.
{
"job_id": "jq_7f3a",
"state": "complete",
"manifest_hash": "sha256:example",
"route": "ibm:hardware-or-simulator",
"artifact_uri": "ipfs://bafy-result",
"artifact_hash": "sha256:result",
"settlement_state": "ready_to_finalize"
}
If your webhook cannot explain what changed, it will create support tickets. If it can, users can automate around it.
What works with IBM quantum computing in 2026
IBM quantum computing is useful when expectations are aligned with the platform. The strongest workloads are explicit, bounded, and tolerant of asynchronous completion.
This is where marketplace operators should start.
Hybrid optimization experiments
Hybrid optimization is a practical early lane because it already assumes a classical loop. The marketplace can run classical steps on normal workers, call quantum execution for the specialized segment, then return a combined artifact.
Good candidates include experiments where the user cares about method, trace, and reproducibility as much as raw speed.
What works:
- bounded parameter loops
- capped shot counts
- simulator dry runs
- explicit backend policy
- artifacted intermediate results
What fails:
- unbounded loops
- hidden provider costs
- no max queue time
- no replay metadata
- pretending every optimization problem benefits
Simulation and education workloads
Simulators are underrated in marketplace design. They let users test manifests, learn workflow semantics, and debug result handling before spending budget or waiting for hardware.
A simulator path also gives the marketplace a safer default for demos and tutorials. It keeps the product honest while still supporting quantum-specific developer experience.
Related reading from our network: video infrastructure teams face a similar split between demo experience and real execution constraints in Fubo streaming architecture for cord cutters and media setups.
Quantum-assisted research queues
Research users often accept asynchronous work if the system is transparent. They want to know the queue state, backend class, policy, and artifact format.
For this audience, the product should optimize for:
- manifest reproducibility
- stable APIs
- exportable artifacts
- clear queue and failure states
- supportable billing records
That is not flashy, but it is what makes a research workflow usable.
What fails when teams implement quantum badly
Quantum projects fail in boring ways. The backend may be advanced, but the product breaks at the seams: unclear state, weak billing policy, missing artifacts, and support teams that cannot answer basic questions.
Selling quantum as instant acceleration
If a product implies that IBM quantum computing will speed up normal AI inference, FFmpeg transcoding, or web API workloads, it is setting itself up for churn.
A video engineer trying to transcode HLS renditions needs CPU/GPU throughput, storage locality, and retryable workers. A model-serving team needs latency, batching, warm pools, and token accounting. Quantum is not the answer to those jobs.
The better positioning is specific: quantum-backed experiments for circuit-based and hybrid workloads.
Ignoring queue time and reproducibility
Queue time is part of the user experience. Reproducibility is part of trust.
What breaks in practice:
- the user cannot tell whether a job is waiting or dead
- support cannot see provider state history
- the same manifest produces different undocumented outputs
- payment finalizes before artifact validation
- users dispute charges because the completion condition was unclear
These are not quantum physics problems. They are product architecture problems.
Treating provider credentials casually
Provider credentials should never end up in random worker containers, browser sessions, or customer scripts. The broker exists to prevent that.
Bad patterns include:
- asking users to paste provider tokens into a public job manifest
- logging secrets during failed submission
- letting workers submit directly to provider accounts
- mixing customer artifacts and provider credentials in the same storage bucket
- giving support operators unscoped access
Credential handling is where experimental systems become real risk.
Payments, settlement, and support for quantum workloads
Quantum marketplace payments need more nuance than pay before run. The job may wait, fail, partially complete, or complete through a fallback route.
The practical question is what the buyer is purchasing.
Escrow for uncertain work
Escrow is a better fit than immediate final settlement. Reserve funds when the job is accepted. Finalize only when the completion rule is satisfied.
Completion rules might be:
- simulator result produced under manifest policy
- hardware result produced under manifest policy
- fallback accepted by user policy
- timeout reached and refund issued
- provider failure confirmed and retry offered
This is similar to how serious billing systems separate invoice creation, payment authorization, fulfillment, adjustment, and reconciliation. Related reading from our network: the same operational separation shows up in invoicing software workflow design.
Reconciliation artifacts
Support teams need records that match the ledger.
A good reconciliation record includes:
- job id
- payer DID
- manifest hash
- accepted route
- final route
- timestamps by state
- artifact hash
- billed amount
- refund amount if any
- reason code
- operator actions
Without this, disputes become archaeology.
Disputes and reruns
Disputes are unavoidable when users run experimental workloads. The fix is not to avoid disputes. The fix is to make them bounded.
Define policy up front:
| Scenario | Default action | Notes |
|---|---|---|
| provider timeout before running | refund | no execution occurred |
| provider failure after submission | retry or refund | depends on provider evidence |
| simulator fallback used without permission | refund | route violated manifest |
| result artifact missing metadata | hold settlement | broker must repair or fail |
| user dislikes valid result | no automatic refund | expectation issue, not execution failure |
Practical rule: Settlement should follow documented state transitions, not support team improvisation.
Operating IBM quantum computing in production-adjacent systems
Production-adjacent is the right phrase for most IBM quantum computing integrations in 2026. The control plane may be production. The quantum backend is usually experimental, quota-limited, or research-oriented.
That means observability matters more, not less.
Metrics that matter
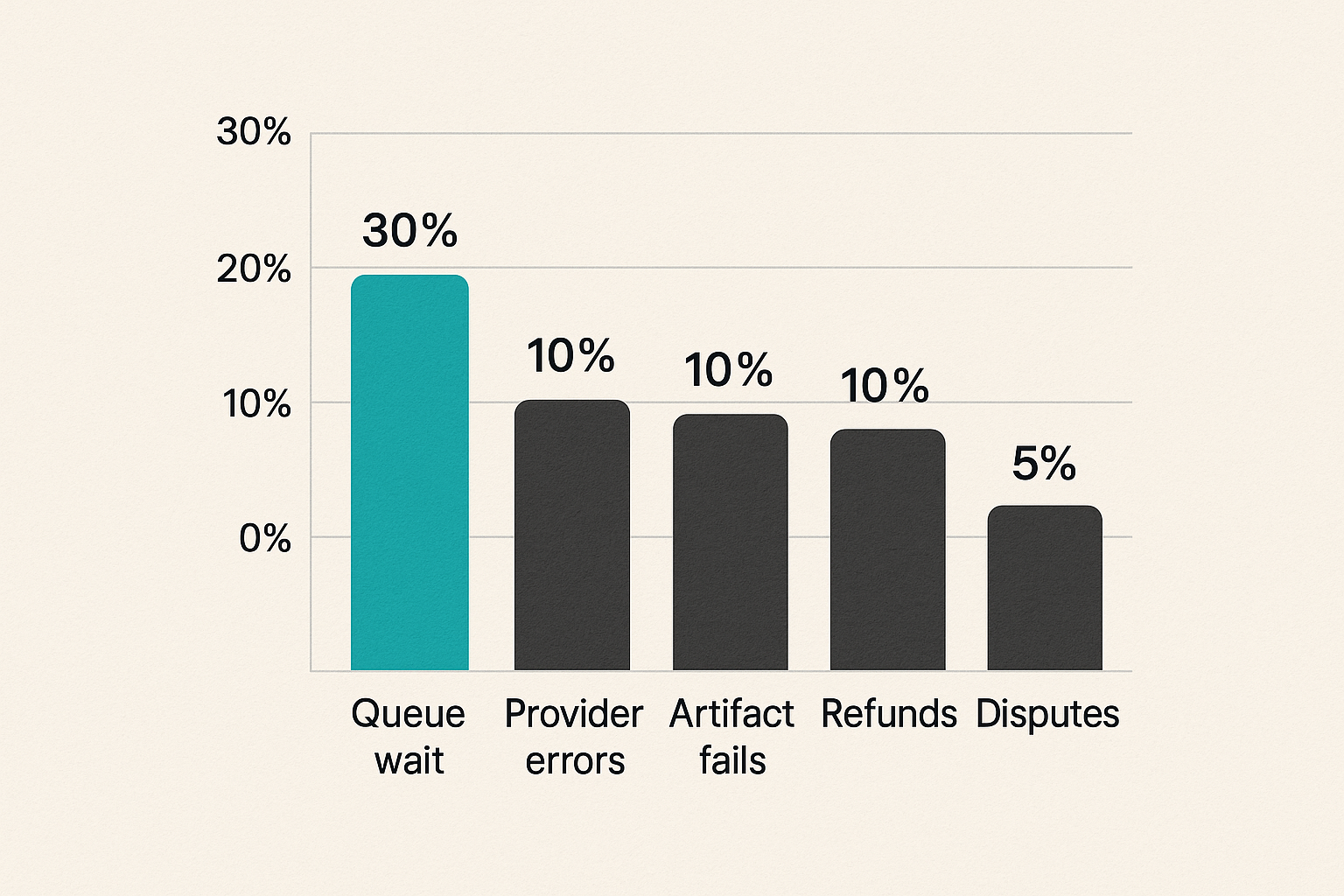
Track metrics that help you operate the workflow:
- accepted jobs by route
- validation failures by reason
- queue wait time
- provider submission errors
- execution duration
- timeout rate
- artifact normalization failures
- refund rate
- dispute rate
- cost per completed job
Do not obsess over vanity metrics like total quantum jobs submitted if half of them are invalid or unsupported.
A useful operator dashboard separates marketplace health from provider health. If the provider is slow but your state machine, refunds, and notifications work correctly, the system is degraded but not broken.
SLOs for experimental backends
Do not promise the same SLO for quantum jobs that you promise for local CPU workers or GPU inference.
Better SLO language:
- validation completes within seconds
- accepted jobs enter a visible queue state
- users receive timeout handling within policy
- artifacts are available after completion
- refunds are issued automatically on defined failures
This is honest and measurable.
Bad SLO language:
- quantum jobs complete in five minutes
- hardware access is always available
- all optimization jobs improve results
- outputs are deterministic without caveats
Runbooks for provider and queue failures
Runbooks should be written before launch, not after the first angry user.
Minimum runbooks:
- Provider API unavailable.
- Provider accepts job but stops returning status.
- Queue exceeds user max wait.
- Artifact normalization fails.
- Broker emits duplicate completion event.
- Payment finalization fails after completion.
- User disputes valid completion.
- Provider credential rotation required.
Each runbook should name the owner, automated action, manual fallback, and user-visible message.
The mistake teams make is treating quantum failure as special. Most failures still map to ordinary distributed system categories: timeout, partial completion, duplicate event, invalid state, credential error, and reconciliation mismatch.
Where c0mpute.com fits in a quantum-ready compute marketplace
c0mpute.com is not trying to turn every workload into a quantum workload. The useful role is different: build a CLI-first decentralized compute marketplace where specialized backends can be integrated behind clear job contracts, identity boundaries, payment flows, and artifacts.
That is the architecture IBM quantum computing needs if it is going to be useful to builders instead of just interesting in a demo.
Fit for technical builders
For AI infrastructure builders, the immediate work is still inference, batching, routing, and artifact handling. For video engineers, it is FFmpeg execution, queues, storage, and retry semantics. For web3 developers, it is identity, payments, settlement, and trust.
Quantum fits when those same primitives can wrap an experimental backend:
- manifest-defined jobs
- DID-based payer and worker identity
- escrow-aware execution
- stateful routing
- signed artifacts
- CLI-first inspection
- supportable reconciliation
If those pieces are missing, adding IBM quantum computing just creates a more expensive failure mode.
Integration pattern
The clean integration pattern is adapter-first:
- Keep marketplace job states generic.
- Add a quantum job type with strict schema.
- Route through a broker, not arbitrary workers.
- Store raw and normalized artifacts.
- Connect settlement to documented completion states.
- Expose everything through CLI and API.
This keeps quantum optional. It also keeps the marketplace sane. Builders can run AI inference, transcoding, and DID-based payment workflows without inheriting quantum-specific complexity unless they request it.
For adjacent implementation notes across decentralized compute modules, the c0mpute blog covers marketplace operations, job states, payment flows, and compute workflow design.
Try c0mpute.com
IBM quantum computing in 2026 is not a shortcut around architecture. It is a reason to make the architecture more explicit: typed jobs, scoped credentials, asynchronous state, signed artifacts, escrow, reconciliation, and honest routing.
If you get those pieces right, quantum can become one more specialized backend in a decentralized compute marketplace. If you skip them, the system will fail in predictable, support-heavy ways.
Try c0mpute.com
You are writing for technical builders interested in decentralized compute, AI inference, FFmpeg transcoding, and DID-based payments. Try c0mpute.com.