A user sends a video in an encrypted chat. On their device it plays fine. On the recipient side it stalls, burns battery, or fails because the codec is wrong. The product team asks for encrypted messaging video transcoding, usually after support tickets pile up.
Teams think the problem is video compression. The real problem is building a private media pipeline where untrusted infrastructure can do useful work without becoming the owner of the conversation.
That changes the conversation. You are no longer asking which FFmpeg flags make smaller files. You are deciding where plaintext exists, who can request compute, how results are verified, how retries behave, and what happens when a worker disappears halfway through a job.
In 2026, this matters because encrypted messaging is no longer just text. Users send voice notes, video clips, screen recordings, livestream fragments, and AI-generated media. If your messaging product cannot normalize video safely, you inherit the worst parts of video infrastructure and secure messaging at the same time.
Table of contents
- Why encrypted messaging video transcoding is a systems problem
- Architecture: keep messages private while compute touches media
- Threat model and ownership boundaries
- Workflow: from encrypted upload to playable renditions
- Decentralized compute changes the bottleneck
- FFmpeg implementation details that matter
- What breaks when teams implement it badly
- Observability, verification, and cost control
- What works in production
- Where c0mpute fits into encrypted messaging video transcoding
Why encrypted messaging video transcoding is a systems problem
The mistake teams make is treating media as an attachment
Text messages are small, structured, and usually easy to encrypt end to end. Video is not. A ten second clip can carry container quirks, orientation flags, variable frame rate, high-bitrate audio, HDR metadata, and a codec the recipient device handles poorly.
The mistake teams make is treating that video as a large attachment with a thumbnail. That works until users expect the same reliability they get from mainstream chat apps: instant preview, smooth playback, quick download, sane bandwidth use, and no obvious privacy downgrade.
Encrypted messaging video transcoding sits between two systems that normally do not like each other:
- Secure messaging wants minimal server knowledge.
- Video infrastructure wants to inspect and transform media.
- Mobile UX wants fast playback on weak networks.
- Operations wants retryable jobs and debuggable failures.
If you ignore that tension, you either ship a private product with bad media UX or a polished media product with weak privacy boundaries.
The practical question is where plaintext exists
The practical question is not whether you can transcode video. FFmpeg can do that. The practical question is where the unencrypted video exists, for how long, under whose control, and with what audit trail.
A useful way to think about it is this: transcoding is a controlled exception to the normal encrypted messaging rule. You are allowing compute to touch media because the recipient needs a playable rendition. That exception must be narrow, observable, and reversible in the architecture.
Practical rule: if you cannot draw the plaintext boundary on a whiteboard, you do not have an encrypted video architecture. You have a storage habit.
The plaintext boundary may sit on the sender device, inside a trusted execution environment, inside an ephemeral worker, or never leave the client at all. Each model has tradeoffs. The wrong model is the one your team cannot operate or explain.
Why now for messaging teams
Messaging workloads are becoming media-heavy. Private communities share clips. Support teams exchange screen recordings. AI agents send generated videos. Video infrastructure engineers know this already: the UI is not the hard part. The hard part is state, formats, retries, and playback compatibility.
For secure messaging teams, the pressure is sharper. Users want privacy and smooth media. They do not care that those requirements fight each other internally. The architecture has to absorb that complexity.
This guest contribution comes from the team at qrypt.chat, where private communication and practical secure messaging are the default lens rather than a feature checkbox.
Architecture: keep messages private while compute touches media
Client-side encryption is the default boundary
In a sane secure messaging design, the client encrypts the message before upload. The server stores ciphertext. Recipients decrypt locally. That model is clean for text, images, documents, and small audio files.
Video complicates the default because recipients may need multiple renditions:
- A low-bitrate preview for weak connections.
- A standard mobile rendition for playback compatibility.
- A thumbnail or animated preview.
- A fallback audio-only extraction.
- A normalized MP4 for older clients.
If all of that happens on the sender device, privacy remains strong but the UX can suffer. Mobile devices overheat, battery drains, uploads are delayed, and older phones produce inconsistent results. If all of it happens server-side, UX improves but privacy collapses unless the server is inside the trust model.
That changes the conversation from encryption as a checkbox to encryption as a workflow constraint.
Transcoding creates a temporary trust exception
A transcoder needs frames. Frames are plaintext media. Even if the file arrives encrypted at rest, the worker doing FFmpeg work needs a decryption path or must receive a plaintext input from a trusted client.
There are four common patterns:
- Client transcodes before encryption.
- Client encrypts, then a trusted backend decrypts and transcodes.
- Client encrypts, then an ephemeral worker decrypts with scoped keys.
- Client encrypts, then a hardware-backed or enclave-backed worker processes inside an attested environment.
None is perfect. The job is to pick the smallest trust exception that your team can actually implement.
Practical rule: do not call a pipeline end-to-end encrypted if your backend can silently decrypt every video forever. Call it what it is, then reduce the trust surface.
A comparison of pipeline models
| Model | Privacy posture | Operator burden | UX quality | Common failure |
|---|---|---|---|---|
| Client-only transcoding | Strongest if implemented well | Medium | Variable | Slow sends and battery drain |
| Backend trusted transcoding | Weak unless backend is trusted by design | Low | High | Server becomes media custodian |
| Ephemeral worker with scoped keys | Better operational balance | High | High | Key lifetime and cleanup bugs |
| Attested compute path | Stronger boundary if verified | High | High | Complex integration and proof handling |
What breaks in practice is not the FFmpeg command. It is the mismatch between the privacy claim and the actual compute path. If a worker can fetch old encrypted blobs, request keys indefinitely, and write outputs without verification, the system is not narrow. It is just distributed.
Threat model and ownership boundaries
Who can see the original video
Start with a blunt question: who can see the original video bytes after the sender taps send?
Possible answers include:
- Only the sender device.
- The sender and recipient devices.
- A backend service during processing.
- A specific worker for a specific job window.
- A compute environment after remote attestation.
Each answer implies different logs, access controls, deletion rules, and incident response procedures. If the backend can see media, operators need to treat that backend like sensitive production infrastructure. If workers can see media, worker identity and lifecycle become part of the messaging security model.
A useful architecture records this as a policy, not a paragraph in a design doc. For example:
media_policy:
plaintext_allowed:
- sender_device
- assigned_transcode_worker
worker_key_ttl_seconds: 900
source_delete_after_success: true
output_requires_hash: true
recipient_decrypts_outputs: true
This is not magic. It is a way to force the implementation to match the promise.
Who can request compute
Encrypted messaging video transcoding should not be an open compute endpoint. If any authenticated user can submit arbitrary FFmpeg jobs with unbounded parameters, you have built a denial-of-service surface.
Requests should be tied to message state:
- The sender created a media message.
- The upload completed.
- The media policy allows the requested renditions.
- The job size fits account limits.
- The worker can only access the assigned input and write assigned outputs.
That last point matters. A worker should not browse storage. It should receive job-scoped access. If the worker fails, expires, or behaves incorrectly, those grants should die with the job.
What metadata still leaks
Even if content stays private, metadata leaks are real. Video size, duration, upload time, recipient count, retry frequency, and processing profile can reveal behavior.
Many teams over-focus on content encryption and ignore media metadata. For some products, that may be acceptable. For high-risk communication, it may not be.
The practical approach is to classify metadata explicitly:
- Required for delivery: message ID, recipient routing, object pointer.
- Required for processing: size class, duration class, profile, deadline.
- Optional for analytics: device type, network type, client version.
- Dangerous by default: exact location, contact graph export, raw filenames.
Practical rule: encrypting the media does not make the workflow private if the job metadata tells the story.
Workflow: from encrypted upload to playable renditions
A numbered implementation sequence
A workable encrypted media pipeline looks like a state machine, not a single upload handler.
- Sender records or selects a video.
- Client probes local metadata such as duration, codec, dimensions, and orientation.
- Client chooses whether to transcode locally or request remote processing.
- Client encrypts the source or an upload package.
- Client uploads to object storage or a relay.
- Backend validates message state and creates a transcode job.
- Worker receives scoped access, decrypts only what it needs, and runs the profile.
- Worker writes encrypted outputs plus manifests and hashes.
- Backend verifies outputs and advances message state.
- Recipient fetches the manifest, selects a rendition, and decrypts locally.
The sequence is boring on purpose. Boring state transitions are easier to secure.
Queue design for media jobs
Video workloads are bursty. A group chat can create a spike. A creator community can create a bigger spike. A single user can upload a long screen recording that blocks smaller jobs if your queue is naive.
Use separate queues or priority lanes:
- Short clips under a duration threshold.
- Long videos or high-resolution inputs.
- Thumbnail-only jobs.
- Retry jobs.
- Dead-letter jobs for operator review.
Queue messages should carry policy and references, not secrets. Do not put raw keys in a generic queue if that queue has broad internal access. Instead, let the worker exchange its job identity for a short-lived grant.
Webhook and state transitions
Treat worker callbacks like external webhooks even if the worker is part of your own fleet. They can be delayed, duplicated, reordered, or forged if you are careless.
A minimal state model:
created -> uploaded -> queued -> processing -> verifying -> ready
-> failed_retryable
-> failed_terminal
-> expired
Every transition should be idempotent. If a worker reports success twice, the second callback should not create a second media object. If a retry completes after a newer retry, the backend should know which result wins.
The mistake teams make is connecting upload success directly to message delivery. That makes the recipient experience depend on a background process the app cannot explain.
Decentralized compute changes the bottleneck
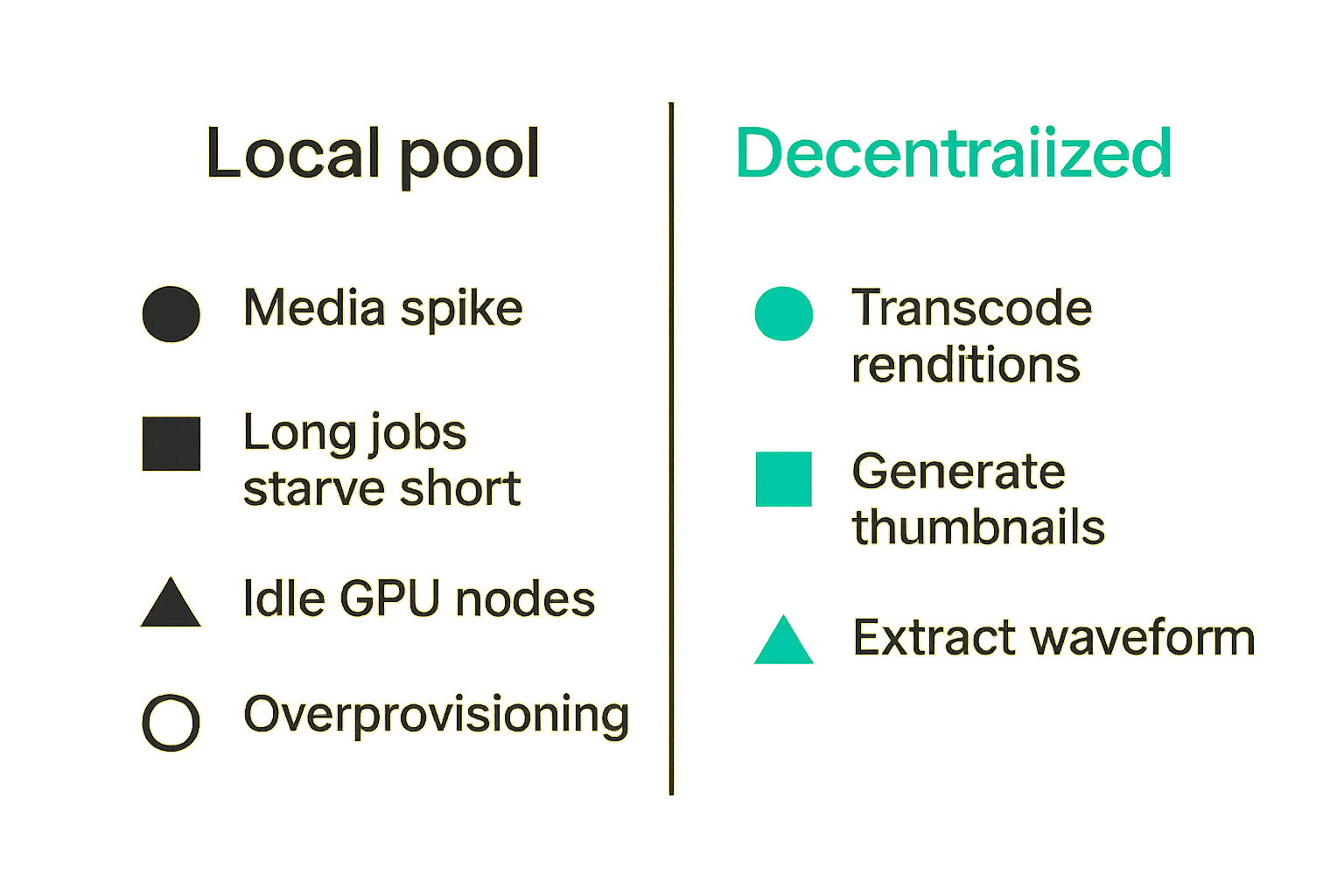
Why local workers do not scale cleanly
A small team can start with a few FFmpeg workers behind a queue. That is usually fine until the workload becomes uneven. The painful moments are predictable:
- A marketing launch creates a media spike.
- A few long jobs starve short messages.
- GPU-capable nodes sit idle while CPU nodes melt.
- Regional users get slow processing because workers are far away.
- Operators overprovision for peak and pay for idle time.
Encrypted messaging video transcoding has another problem: you may not want all jobs to land on the same internal worker pool. If the worker pool is a privacy-sensitive boundary, concentration increases blast radius.
Decentralized compute does not remove architecture work. It changes the scaling model. Instead of owning every worker, you define jobs, policies, payments, verification, and settlement between requesters and compute providers.
What decentralized workers are good at
Decentralized compute is useful when work can be packaged, bounded, and verified. FFmpeg jobs often fit that shape if you keep profiles tight.
Good fit:
- Transcode this input into these renditions.
- Generate these thumbnails.
- Extract waveform data.
- Normalize audio track.
- Produce a manifest and output hashes.
Bad fit:
- Long-running interactive sessions with unclear end state.
- Jobs that require broad backend database access.
- Pipelines where output correctness cannot be checked.
- Workloads with unbounded user-defined FFmpeg filters.
The practical question is whether you can hand a worker a sealed job envelope and verify the envelope came back correctly.
What still needs to stay centralized
Even in a decentralized compute architecture, some things should remain under application control:
- User identity and authorization.
- Message graph and recipient permissions.
- Key policy and grant issuance.
- Final message state transitions.
- Abuse controls and quota decisions.
- User support context.
Do not outsource ownership of the conversation. Outsource bounded compute. That distinction keeps the messaging system coherent.
| Responsibility | Messaging app | Compute worker |
|---|---|---|
| Decide who can see a message | Yes | No |
| Run FFmpeg profile | No | Yes |
| Issue scoped decrypt grant | Yes | No |
| Store final message state | Yes | No |
| Produce output hash | No | Yes |
| Verify output before delivery | Yes | No |
FFmpeg implementation details that matter
Use profiles, not one-off commands
Letting clients or users submit arbitrary FFmpeg arguments is a bad default. It makes costs unpredictable and expands your attack surface. Use named profiles.
Example profile shape:
profiles:
mobile_mp4_720p:
container: mp4
video_codec: h264
audio_codec: aac
max_width: 1280
max_height: 720
max_bitrate: 1800k
faststart: true
preview_360p:
container: mp4
video_codec: h264
audio_codec: aac
max_width: 640
max_height: 360
max_bitrate: 550k
duration_limit_seconds: 30
Profiles give operators something to reason about. They also let you price and route jobs. A 360p preview and a 4K transcode should not be treated as the same unit of work.
Make outputs deterministic enough to verify
Perfect byte-for-byte determinism can be hard across FFmpeg versions, hardware encoders, and build flags. But you can still make outputs deterministic enough for operational verification.
Verify:
- Expected number of renditions exists.
- Duration is within tolerance.
- Dimensions match the profile.
- Codec and container match the profile.
- Output size is under expected bounds.
- Hashes match what the worker reported.
- Media is decryptable by the intended recipient path.
If the worker only reports success and you never inspect the result, you have no meaningful boundary. Verification is the step that turns remote compute from hope into a workflow.
Handle mobile video edge cases
Mobile video is messy. Production systems need to handle:
- Rotation metadata that players interpret differently.
- Variable frame rate screen recordings.
- HEVC sources from newer phones.
- HDR sources that look washed out after conversion.
- Videos with no audio stream.
- Audio drift on long recordings.
- Corrupt partial uploads.
What fails is assuming the source file is normal because it came from a phone. Phones are where many of the weird files come from.
Practical rule: always probe before processing, and store the probe result with the job. It is the first artifact support will need when playback breaks.
What breaks when teams implement it badly
Plaintext gets parked in the wrong place
The most dangerous failure mode is not a dramatic cryptographic flaw. It is boring plaintext persistence.
Examples:
- Temporary files are left on worker disks.
- Debug logs include signed URLs or key material.
- Failed jobs keep decrypted intermediates.
- Object storage lifecycle rules only cover successful outputs.
- Operators copy samples into local machines to debug playback.
This is where secure systems drift. The design says plaintext is temporary, but the implementation leaves artifacts.
A better pattern is to make cleanup part of the worker contract and part of backend verification. Workers should use isolated working directories, delete intermediate files, and report cleanup state. Backends should expire grants aggressively and apply lifecycle policies to all job prefixes, not just happy paths.
Retries create duplicate media states
Retries are necessary. They are also where media systems get weird.
If a worker times out but later completes, and a retry also completes, which output is canonical? If the sender cancels a message while a worker is processing, can the callback resurrect it? If a recipient has already downloaded a preview, what happens when the final rendition arrives?
These are state questions. Solve them before writing worker code.
What works:
- Use job attempt IDs.
- Make callbacks idempotent.
- Store canonical output pointers once.
- Reject stale attempt completions.
- Keep message deletion higher priority than job completion.
What fails:
- Using filename conventions as state.
- Treating any success callback as final.
- Letting workers choose output locations.
- Retrying without attempt lineage.
Support cannot explain failures
Private systems are hard to support because operators should not inspect content. That is good. It also means your non-content telemetry needs to be strong.
Support should be able to answer:
- Did upload complete?
- Was remote processing requested?
- Which profile was used?
- Did the worker start?
- Did verification fail?
- Is the recipient missing keys or missing media?
- Is playback failing because of network, codec, or authorization?
If the only support answer is ask the user to resend, the system is not production-ready.
Observability, verification, and cost control
Metrics that operators actually need
Do not drown the team in dashboards. Track metrics that map to decisions.
Useful operational metrics:
- Queue time by profile.
- Processing time by profile and duration bucket.
- Failure rate by worker class.
- Verification failure reason.
- Retry count per job.
- Output size compared to input size.
- Recipient playback success events.
- Cost per processed minute.
A chart that shows average processing time across all jobs is usually useless. A ten second preview and a ten minute 1080p transcode should not share one average.
Verification before delivery
The backend should not mark media ready just because a worker says the job completed. Put a verification gate between processing and delivery.
Verification can be lightweight:
- Fetch worker manifest.
- Check job ID, attempt ID, profile, and input hash.
- Probe outputs.
- Validate dimensions, codec, duration, and size limits.
- Confirm encryption metadata exists.
- Store canonical output references.
- Advance message state to ready.
For sensitive workloads, add stronger verification, duplicated processing, or attestation checks. The right level depends on threat model and cost tolerance.
Cost controls for bursty workloads
Video costs are spiky. Secure messaging teams often learn this late because early users send text and images. Then one community starts sharing clips and the queue changes shape.
Cost controls should be policy-driven:
- Limit source duration by account or room.
- Use default mobile profiles instead of preserving source quality.
- Generate previews first and high-quality renditions lazily.
- Apply per-user and per-room quotas.
- Route expensive profiles to appropriate worker classes.
- Expire unclaimed outputs after a retention window.
The goal is not to degrade UX. The goal is to avoid letting one media pattern define your infrastructure bill.
What works in production
Separate message security from media processing
The cleanest systems separate message security from media processing while connecting them through explicit policy.
Message security owns:
- Sender and recipient authorization.
- Key agreement and message encryption.
- Message state.
- Deletion and retention semantics.
Media processing owns:
- Probing.
- Transcoding.
- Thumbnailing.
- Packaging.
- Output manifests.
The bridge is a job policy: what may be processed, by whom, for how long, and into which outputs.
This separation prevents a common architecture smell: the media worker slowly becomes a privileged messaging backend. Once that happens, every FFmpeg bug becomes a messaging security issue.
Design for failed workers
Assume workers fail. Assume they fail after reading input, before writing output, after writing partial output, after sending a callback, and before cleanup. Then design the system so none of those failures creates a privacy or state problem.
A resilient worker model includes:
- Job-scoped credentials.
- Short key TTLs.
- Attempt IDs.
- Dedicated temporary directories.
- Output writes to attempt-specific prefixes.
- Cleanup on success and failure.
- Backend lifecycle cleanup for abandoned attempts.
This is boring infrastructure discipline. It is also what keeps private video workflows from becoming incident factories.
Keep the recipient experience simple
Recipients should not see your pipeline. They should see a playable video, a useful loading state, or a clear failure.
Good recipient states:
- Preparing video.
- Preview available.
- Downloading secure media.
- Playback unsupported on this device.
- Sender removed this media.
- Video expired.
Bad states:
- Transcode job failed.
- Worker timeout.
- Manifest missing.
- Decryption grant expired.
Those bad states may be true internally, but they are not user-facing language. Secure products lose trust when users cannot tell whether media is private, broken, or gone.
Where c0mpute fits into encrypted messaging video transcoding
A good fit for burst FFmpeg jobs
c0mpute.com is interesting for this problem because encrypted messaging video transcoding is exactly the kind of workload that benefits from bounded, CLI-friendly compute. You can package an FFmpeg job, submit it to available compute, verify the result, and keep the messaging app in control of keys and state.
That does not mean every private messaging app should push all media work to a decentralized marketplace on day one. It means the architecture should make compute replaceable. If your job contract is clean, you can run locally, on your own fleet, or across decentralized workers without rewriting the messaging layer.
The practical pattern is:
- Define profiles.
- Package job inputs.
- Scope access.
- Run compute.
- Verify outputs.
- Advance message state.
Whether the worker is internal or external becomes an implementation choice, not a product rewrite.
How to think about product boundaries
Use c0mpute for the compute boundary, not the trust boundary. Your application should still own identity, authorization, key policy, and final delivery semantics.
That is the architecture that scales cleanly. The messaging app says what is allowed. The compute layer does the bounded work. The backend verifies. The recipient gets a playable encrypted result.
The mistake teams make is expecting infrastructure to solve product semantics. It will not. Decentralized compute can give you capacity and flexibility, but your workflow still needs state, verification, and ownership.
For builders working on private media, AI video workflows, or secure collaboration tools, this is the useful framing: encrypted messaging video transcoding is not a feature. It is a contract between clients, keys, storage, compute, and recipients.
Try c0mpute.com
Build and run bounded FFmpeg, AI, and media workloads on decentralized compute infrastructure. If you are designing encrypted messaging video transcoding, start with a clean job boundary and test the workflow on Try c0mpute.com.