Edge computing sounds simple until you put it in production. You move compute closer to users, workers, cameras, devices, or content. Latency drops. Cloud bills improve. Everyone gets a clean architecture diagram.
Then the first real job fails halfway through a transcode. A worker disappears during inference. A customer asks why two outputs differ. Your payment system settles before verification. Your logs are split across five machines you do not control.
Teams think the problem is where the compute runs. The real problem is how work is routed, verified, paid for, retried, and observed when the runtime is distributed.
That changes the conversation. Edge computing is not a geography feature. For decentralized compute builders, AI infrastructure teams, and video engineers, it is an execution architecture. The practical question is not “edge or cloud?” It is “which jobs can safely leave the centralized control plane, and what workflow proves they completed correctly?”
Table of contents
- Why edge computing is an execution architecture not a location
- What changes in 2026 for edge computing
- Edge computing architecture components that matter
- Edge computing versus cloud versus decentralized compute
- A practical workflow for routing edge jobs
- AI inference at the edge
- FFmpeg transcoding and media pipelines at the edge
- Payments identity and trust boundaries
- What breaks when teams implement edge computing badly
- Implementation checklist for builders
- Where c0mpute.com fits
Why edge computing is an execution architecture not a location
The mistake teams make
The mistake teams make is treating edge computing as a deployment target. They draw a cloud region, draw a few edge nodes, and assume the hard part is choosing hardware.
Hardware matters, but it is not the control point. The control point is the job lifecycle:
- Who accepts the job?
- What input is the worker allowed to see?
- How does the worker prove it ran the requested command?
- What happens when it fails halfway through?
- When does payment settle?
- Which logs explain the result?
If you cannot answer those questions, you do not have edge computing. You have remote execution with optimistic assumptions.
A useful way to think about it is this: cloud computing centralizes trust and operations. Edge computing decentralizes execution. Decentralized compute marketplaces go further by decentralizing worker ownership too. Each step creates more flexibility, but also more state to manage.
Practical rule: Do not move a workload to the edge until you can describe the job state machine from requested to verified to settled.
The real unit is a job
In production, the unit of edge computing is not a server. It is a job.
For AI inference, a job might be: run this model version against this prompt or tensor input, with this maximum token budget, and return a signed output plus timing metadata.
For FFmpeg, a job might be: transcode this segment from mezzanine input to a 1080p HLS rendition with these codec settings, then return output hashes and probe data.
For web3 compute, a job might include identity, payment terms, escrow status, worker reputation, and verification policy.
That job definition becomes the contract between the client, router, worker, verifier, and settlement layer. If the contract is vague, every downstream system becomes a support queue.
What changes in 2026 for edge computing
AI inference moved closer to users
AI inference changed the edge conversation. It is not just about static caching or IoT telemetry anymore. Builders now care about interactive latency, GPU availability, model placement, privacy boundaries, and per-request cost.
Putting inference closer to users can help, but only when the workflow supports it. If a model takes 40 seconds to cold start, shaving 30 milliseconds of network latency is not the win. If a worker returns an unverifiable result, low latency just gives you bad answers faster.
The practical question is: which inference jobs are safe and useful to run outside your primary cluster?
Good candidates often have clear inputs, bounded runtime, measurable output quality, and low sensitivity. Bad candidates require private context, complex tool access, strict deterministic behavior, or heavy shared state.
Video work is still bursty
Video remains one of the cleanest edge computing use cases because transcoding is expensive, parallelizable, and often bursty. A live event, creator upload spike, or archive migration can overwhelm fixed infrastructure.
The edge helps when you can split work into independent units. Segment-based transcoding, thumbnail generation, loudness normalization, and probe jobs are easier to distribute than one giant monolithic render.
Related reading from our network: teams building local streaming and media automation face similar reliability tradeoffs around wake, availability, and playback paths in Wake Tech for Torrent, IPTV, and Home Media.
What breaks in practice is not the FFmpeg command. It is retry logic, output validation, and knowing which worker produced which artifact when a customer reports a broken rendition.
Payments and identity became part of the control plane
In centralized cloud, payment is mostly an account-level billing problem. In a compute marketplace, payment becomes part of dispatch.
A worker may not start until escrow is funded. A client may not release funds until verification passes. A router may prefer workers with better reputation, lower price, or stronger availability. A DID may identify the client, the worker, or both.
This is why edge computing for decentralized networks is not just infrastructure. It is a market design problem attached to a runtime system.
Edge computing architecture components that matter
Job router
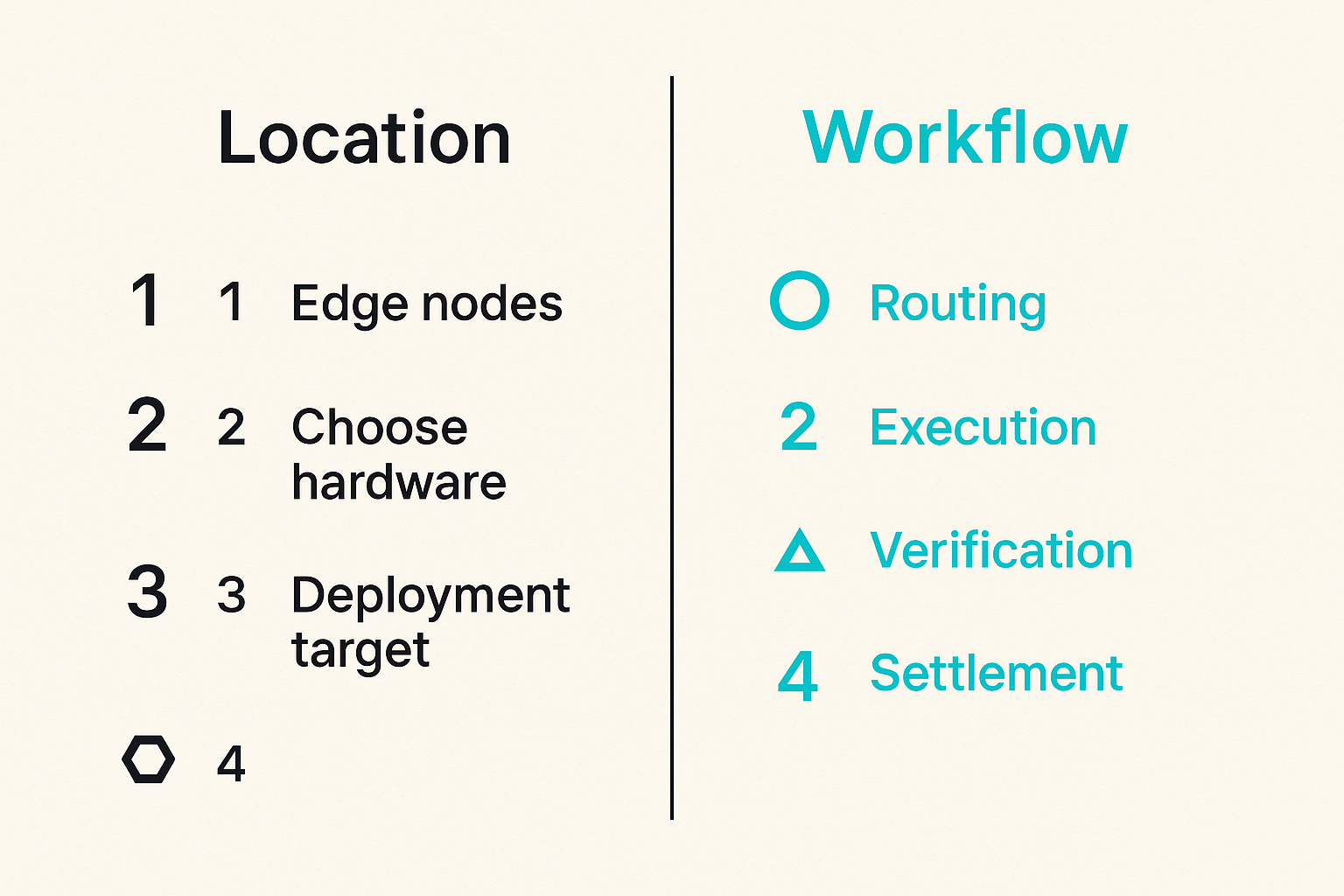
The job router is the decision engine. It receives work, evaluates constraints, selects workers, tracks state, and handles retries.
A minimal router needs to know:
- job type: inference, transcode, probe, batch, validation
- required hardware: CPU, GPU, RAM, storage, codec support
- locality preferences: region, network distance, data proximity
- trust policy: allowlist, reputation threshold, redundancy level
- price ceiling: maximum acceptable cost
- deadline: hard or soft timeout
The router is where edge computing becomes operational. Without it, clients have to choose workers directly, which usually pushes complexity into application code.
Worker runtime
The worker runtime executes the job. It should be boring. Boring means predictable inputs, constrained execution, explicit output paths, health checks, and clear failure codes.
For CLI-first builders, the worker contract should be visible at the command line. A job runner that only works through a dashboard will slow down debugging.
Example shape:
compute-worker run \
--job-id job_8f2a \
--input s3://bucket/input/seg-001.ts \
--command "ffmpeg -i input.ts -c:v libx264 -preset fast output.mp4" \
--output ./out \
--timeout 600
That command is not the whole system. It is the execution surface. Around it you still need identity, dispatch, logs, verification, and settlement.
Storage and data movement
Edge computing fails when teams ignore data movement. Moving a 4 GB mezzanine file to a cheap worker can cost more time and money than using a closer expensive worker.
Treat data location as a first-class routing input. For media, segment early. For inference, cache model weights close to workers. For batch jobs, avoid dispatching work to nodes that must download the same large dependency repeatedly.
A practical storage plan includes:
- immutable input references
- content-addressed output hashes
- short-lived read credentials
- separate paths for logs and artifacts
- retention rules for failed jobs
Practical rule: If the input is large, route by data proximity before you route by worker price.
Settlement and reputation
Settlement is not a billing afterthought. It controls incentives.
If workers get paid when they claim completion, low-quality workers can drain the system. If clients can reject work without evidence, good workers will leave. The architecture needs a verification step that both sides understand.
Reputation should not be a single vanity score. Track dimensions:
- completion rate by job type
- median runtime by hardware class
- verification failure rate
- timeout frequency
- dispute history
- recent availability
That gives the router useful inputs instead of a vague trust signal.
Edge computing versus cloud versus decentralized compute
Where cloud still wins
Cloud still wins when workloads need strong central consistency, managed databases, private networking, mature compliance controls, and deep operational tooling. If your system depends on a large shared stateful service, pushing execution to the edge may create more complexity than value.
Cloud also wins for early product discovery. If you do not yet know your workload shape, centralize first. Measure job duration, data size, failure modes, and cost drivers. Then decide what can move.
The mistake is treating edge computing as a moral upgrade over cloud. It is not. It is a different tradeoff.
Where edge wins
Edge wins when the job is close to the user, close to the data, or naturally parallel.
Examples:
- interactive inference where regional latency matters
- camera-adjacent processing
- media segment transcoding
- batch image or audio processing
- validation jobs near generated artifacts
- local preprocessing before centralized aggregation
The common pattern is bounded work. The input and output are defined. The runtime is measurable. The worker does not need long-lived access to your core database.
Where decentralized marketplaces fit
Decentralized compute marketplaces fit when you want capacity from many independent providers and can tolerate heterogeneous infrastructure. This is especially useful for bursty workloads and builder workflows where CLI access, price discovery, and modular job types matter.
Comparison matters more than slogans:
| Approach | Best for | Main risk | Operational requirement |
|---|---|---|---|
| Central cloud | Stateful systems, managed services, predictable governance | Cost concentration and regional dependency | Strong account and infrastructure management |
| Traditional edge | Low-latency regional execution, device-adjacent processing | Fragmented deployment and monitoring | Fleet orchestration and observability |
| Decentralized compute | Bursty jobs, marketplace capacity, web3-native settlement | Worker trust and inconsistent performance | Routing, verification, reputation, escrow |
That changes the conversation. Decentralized edge computing is not about replacing every cloud service. It is about moving the right jobs into a market where execution can be bought, verified, and settled.
A practical workflow for routing edge jobs
Define job classes
Start with job classes, not infrastructure. A job class describes repeatable work with known constraints.
Example classes:
job_classes:
ffmpeg_hls_1080p:
runtime: ffmpeg
max_duration_seconds: 900
input_max_mb: 512
requires_gpu: false
verification: ffprobe_hash
retry_policy: segment_retry
llama_infer_small:
runtime: inference
model: llama-small-q4
max_tokens: 1024
requires_gpu: true
verification: schema_and_sampling
retry_policy: duplicate_on_timeout
This makes routing explicit. It also gives you a clean way to reject jobs that do not belong at the edge.
Score workers before dispatch
A router should score workers before assigning work. The score does not need to be complex at first. It needs to be visible and explainable.
A simple scoring model:
- Filter workers that cannot run the job.
- Remove workers below the reputation threshold.
- Prefer workers near the input data or user.
- Penalize workers with recent timeouts.
- Compare expected price against the job ceiling.
- Dispatch to one worker or multiple workers depending on verification needs.
For teams building against c0mpute, the CLI reference and cookbook in the c0mpute docs are the right place to map these concepts into install, identity, worker, transcode, inference, reputation, and health-check workflows.
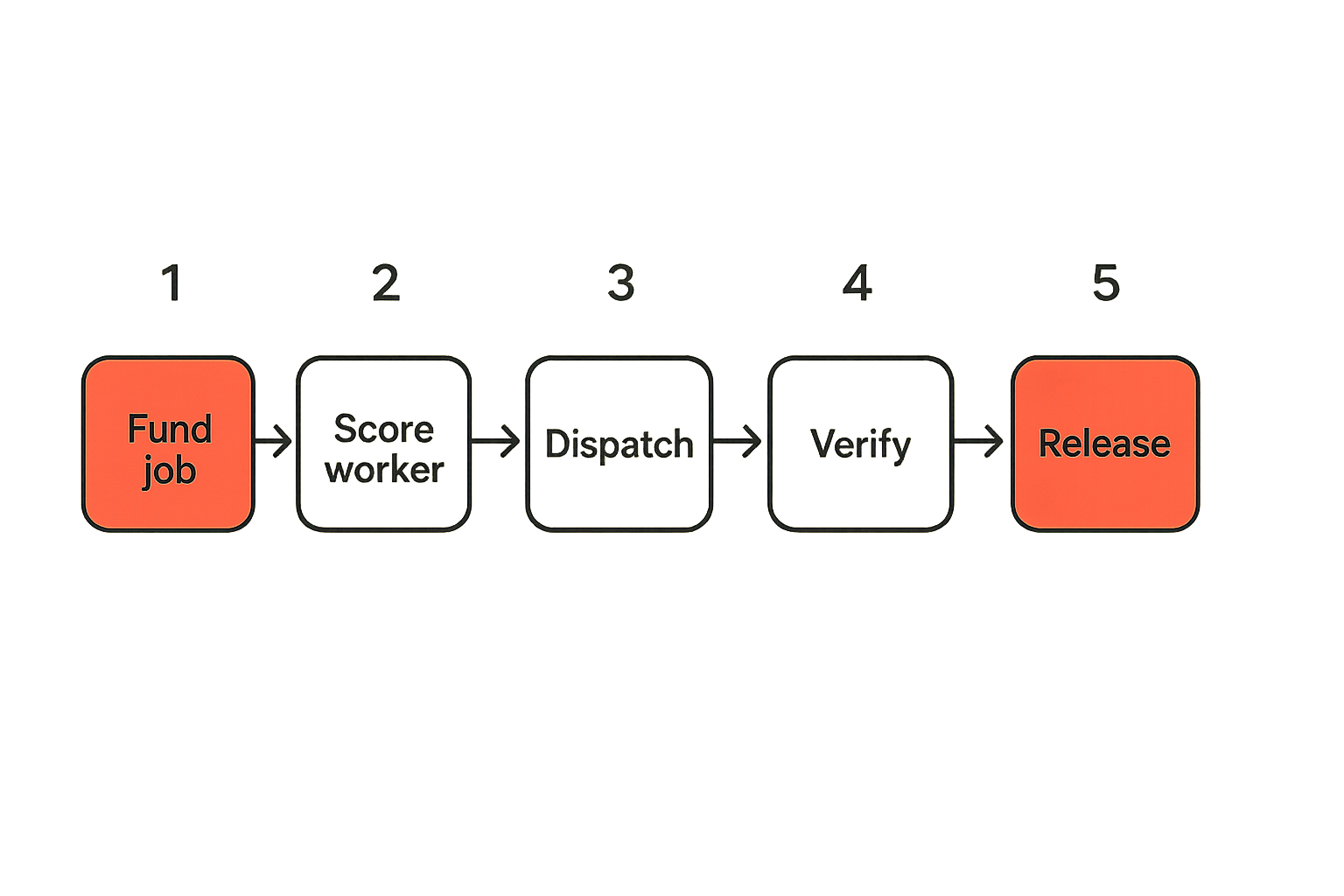
Verify outputs before settlement
Verification has to happen before settlement. That is the line that keeps a decentralized compute marketplace from becoming a trust fall.
For FFmpeg, verification may include output existence, duration, codec, bitrate range, resolution, segment count, playable manifest, and content hash.
For inference, verification is harder. You may validate schema, token limits, deterministic settings where possible, duplicate execution for high-value requests, or compare output against expected constraints. Not every inference result can be fully proven cheaply, so the policy should match the risk.
Practical rule: Verification does not need to be perfect for every job, but it must be explicit before money moves.
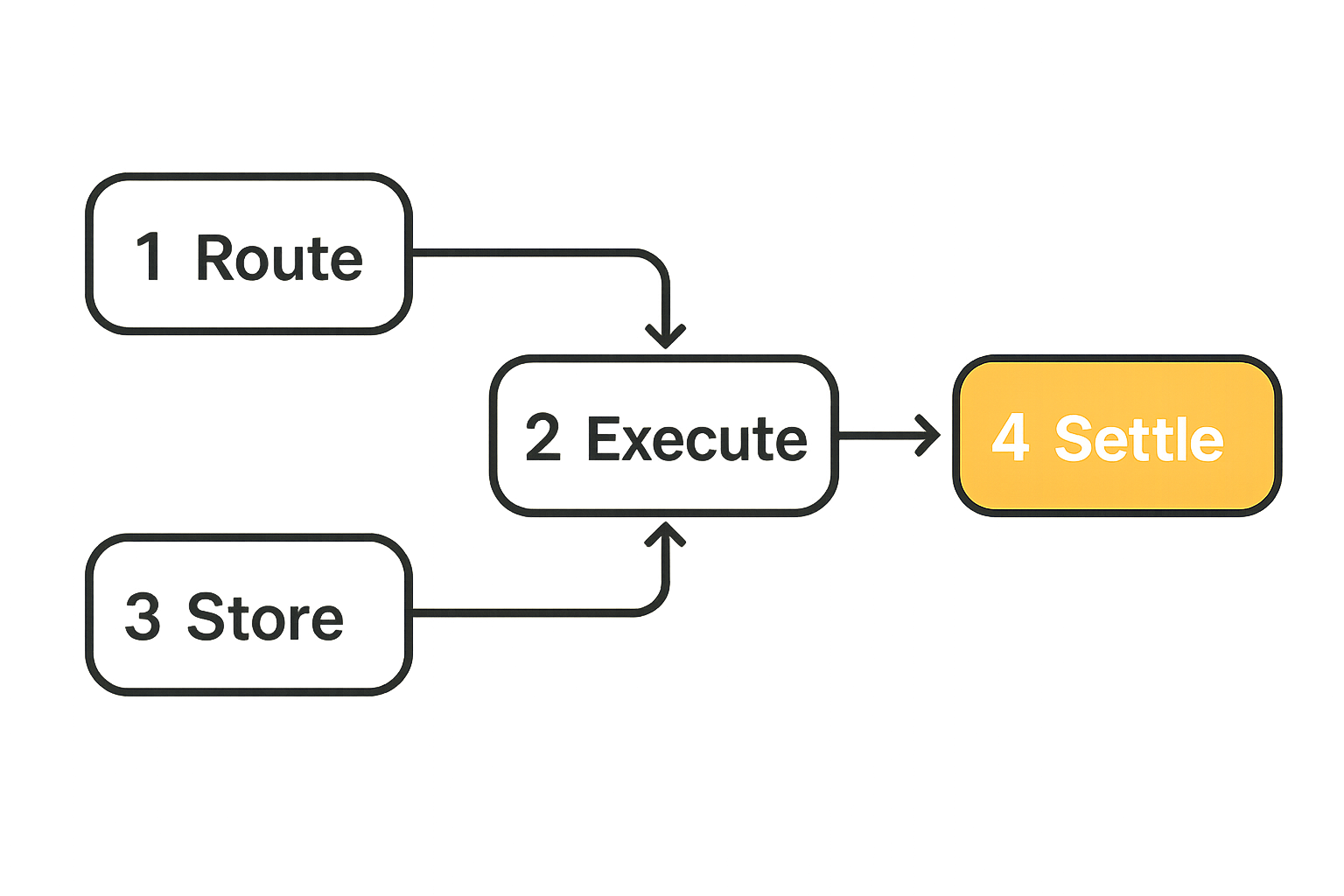
A minimal workflow looks like this:
- Client creates a job with constraints and funded escrow.
- Router selects a worker based on capability, locality, price, and reputation.
- Worker pulls immutable input and executes in a constrained runtime.
- Worker uploads artifacts, logs, and metadata.
- Verifier checks output against the job policy.
- Settlement releases payment or opens a dispute path.
- Reputation updates based on measurable outcome.
This is the core loop. Everything else is optimization.
AI inference at the edge
Latency is not the only metric
Edge computing is often sold on latency. For AI inference, latency is only one metric.
Track at least:
- time to first token or first byte
- total generation time
- model cold-start time
- queue time before execution
- cost per successful request
- output validation failure rate
- retry rate by worker class
If your queue time dominates, add capacity or improve routing. If cold starts dominate, change model placement. If validation failures dominate, tighten worker selection or reduce job complexity.
The practical question is whether moving inference to the edge improves the user-visible workflow, not whether the server is geographically closer.
Model placement and cold starts
Model weights are the hidden data gravity in AI edge architecture. A worker with a GPU is not useful if it spends most of the request downloading weights.
A useful model placement strategy includes:
- pinning popular models to high-reputation workers
- routing by cached model availability
- using smaller quantized models for latency-sensitive jobs
- prewarming workers for expected demand windows
- separating experimental models from production routes
For decentralized networks, model placement is also an incentive problem. Workers need a reason to cache useful models. Clients need a way to discover workers that already have them.
Guardrails for untrusted workers
Not every inference job belongs on an untrusted worker. If the prompt includes private customer data, internal code, credentials, or regulated information, treat it differently.
Guardrails can include:
- redacting sensitive input before dispatch
- routing private jobs only to trusted or allowlisted workers
- encrypting artifacts at rest
- limiting tool access for remote inference
- using duplicate execution for high-value outputs
- logging model version, prompt hash, and worker identity
This is not paranoia. It is basic boundary design. Edge computing expands the execution surface. Your security model has to expand with it.
FFmpeg transcoding and media pipelines at the edge
Segment first then distribute
FFmpeg workloads are good edge candidates when you segment first. Large monolithic jobs are fragile. Segment-level jobs are easier to retry, verify, parallelize, and price.
A common workflow:
- Normalize source metadata.
- Split into time-based segments.
- Dispatch segment transcodes to workers.
- Verify each segment with ffprobe and hashes.
- Assemble manifests.
- Run playback checks.
The CLI shape might look like this:
ffmpeg -i input.mov \
-map 0:v:0 -map 0:a:0 \
-c:v libx264 -preset fast -g 48 \
-c:a aac \
-f hls -hls_time 6 \
out/master.m3u8
In a distributed system, each segment or rendition becomes a job with its own state and verification.
Make retries cheap
Retries should be boring. If retrying a failed transcode requires restarting a two-hour job, the workflow is wrong.
Cheap retries come from:
- small job units
- immutable inputs
- idempotent job IDs
- deterministic output paths
- worker timeouts shorter than user deadlines
- partial result cleanup
Idempotency matters. A worker may receive the same job twice after a timeout. The system should not create duplicate billable outputs or corrupt manifests.
Validate media deterministically
Media validation can be more deterministic than AI validation. Use that advantage.
Check:
- container format
- codec and profile
- resolution
- duration tolerance
- audio presence
- segment count
- keyframe interval
- output hash where applicable
- manifest references
Do not rely on “file exists” as success. A broken media file can exist. A partial upload can exist. A playable-looking manifest can reference missing segments.
Payments identity and trust boundaries
DIDs as worker and client identity
DIDs are useful because decentralized compute needs stable identity without assuming one central account system. A worker identity can sign job acceptance, output metadata, and health statements. A client identity can sign job requests and payment authorization.
This gives the system an audit trail:
- client requested this job
- worker accepted these terms
- verifier evaluated this artifact
- settlement followed this policy
Identity does not make bad workers good. It makes behavior attributable, which is required for reputation and dispute handling.
Escrow changes incentives
Escrow changes the worker-client relationship. The worker knows funds are available. The client knows funds do not release until policy conditions are met.
Related reading from our network: payment teams face the same state-machine problem around checkout, webhooks, settlement, and reconciliation in Blockchain Payment Gateway Architecture.
For compute, escrow should be tied to job state:
| State | Payment behavior | Risk reduced |
|---|---|---|
| Requested | No worker paid | Prevents payment for unaccepted work |
| Funded | Worker can safely start | Reduces non-payment risk |
| Submitted | Funds still locked | Prevents premature settlement |
| Verified | Funds released | Aligns payment with useful output |
| Disputed | Funds paused | Creates review path |
The mistake teams make is bolting payment on after execution. In decentralized edge computing, payment is part of the workflow.
Reconciliation beats guesswork
Reconciliation is how operators stay sane. You need to match job records, worker submissions, verifier decisions, escrow movements, and user-facing invoices.
At minimum, every job should have:
- stable job ID
- client DID
- worker DID
- input hash or immutable reference
- output hash or artifact reference
- verification result
- settlement transaction reference
- timestamps for each state transition
When support asks “what happened?” you should not be grepping five systems manually.
What breaks when teams implement edge computing badly
Hidden egress costs
The first failure mode is hidden egress. Teams route jobs to cheap workers and then discover the data path is expensive or slow.
This happens when price scoring ignores input size, output size, and dependency downloads. For AI, model weights can dwarf request payloads. For media, mezzanine files can dominate the whole job.
Fix it by making data movement visible in routing. A worker price without transfer cost is not a real price.
No observability across workers
The second failure mode is observability. A centralized service can often rely on standard logging, metrics, and tracing. A distributed worker network cannot assume that.
You need a job event stream:
{
"job_id": "job_8f2a",
"worker_did": "did:example:worker123",
"state": "submitted",
"artifact_hash": "sha256:...",
"duration_ms": 184220,
"exit_code": 0,
"timestamp": "2026-06-12T10:15:30Z"
}
Operators should also monitor network health and availability. A public c0mpute status page is useful when builders need to separate their own job logic from network-level incidents.
Trust assumptions leak into support
The third failure mode is pretending trust decisions are invisible. They are not. They show up as support tickets.
If a client disputes a result, you need evidence. If a worker claims it completed a job, you need artifacts. If a verifier rejects output, you need the reason.
Support becomes expensive when the architecture cannot explain itself.
Practical rule: Every distributed job needs enough metadata for a human operator to reconstruct the decision without asking the worker to explain it later.
Implementation checklist for builders
What works
What works is starting narrow. Pick one job class where edge execution has a clear advantage.
Good first choices:
- FFmpeg probe jobs
- thumbnail generation
- HLS segment transcoding
- small batch inference
- embedding generation for non-sensitive content
- validation jobs for generated artifacts
Then build the loop end to end: request, route, execute, verify, settle, observe.
A useful checklist:
- Define job schema.
- Define worker capability schema.
- Use immutable input references.
- Add timeouts and retry limits.
- Capture logs and exit codes.
- Verify outputs before settlement.
- Track worker reputation by job type.
- Reconcile payment state with job state.
What fails
What fails is trying to move a whole application to the edge at once. Databases, queues, secrets, admin tools, and support workflows do not magically become distributed because one compute step moved.
Also avoid these traps:
- routing only by lowest price
- accepting unverifiable outputs
- mixing experimental and production workers
- using mutable input paths
- treating all GPUs as equivalent
- ignoring cold starts
- paying on submission instead of verification
- logging only on the worker
Related reading from our network: SaaS teams dealing with role design and workflow ownership hit a similar issue when they hire before defining the work, covered in Software Engineer Jobs in 2026.
The operator lesson is the same: define the workflow before adding capacity.
Minimum viable production path
A minimum viable production path for edge computing should be small but complete:
- Choose one job class with bounded inputs and outputs.
- Write the job schema and verification policy.
- Build a CLI path that can run locally and remotely.
- Register workers with capability metadata.
- Implement routing with reputation and data locality.
- Store job events centrally.
- Verify outputs automatically.
- Release payment only after verification.
- Add a manual dispute path.
- Measure cost, latency, retry rate, and support load.
Do not skip step 8. It is the difference between a compute marketplace and a queue of hopeful promises.
Where c0mpute.com fits
Product fit for decentralized edge jobs
c0mpute.com is built around the parts of edge computing that usually get hand-waved: CLI workflows, decentralized workers, FFmpeg transcoding, AI inference, DID-based payments, reputation, and health checks.
The fit is strongest when you have jobs that can be packaged, routed, verified, and settled independently. That includes media transforms, inference calls, and modular compute tasks where decentralized capacity is useful but blind trust is not acceptable.
This is not a replacement for your whole cloud architecture. It is a way to move specific execution units into a decentralized compute network while keeping the control plane understandable.
The practical question is: can your workload be expressed as a job with clear input, output, verification, and payment rules? If yes, edge computing becomes much easier to reason about.
Try c0mpute.com
c0mpute.com is for technical builders interested in decentralized compute, AI inference, FFmpeg transcoding, and DID-based payments.
Try c0mpute.com and start modeling edge computing as a job workflow, not just a place to run servers.