Cloud computing services used to feel like a solved problem: pick a provider, choose an instance type, wire up storage, and ship. That works until the workload stops looking like a normal web app.
AI inference has bursty GPU demand. FFmpeg transcoding turns storage and egress into operational problems. Web3 systems add identity, settlement, and trust boundaries that the average cloud dashboard does not model well.
Teams think the problem is choosing cheaper cloud computing services. The real problem is designing a compute workflow that can survive variable demand, untrusted workers, payment events, job retries, and support tickets.
That changes the conversation. The practical question is not, which cloud is best? It is, where should a job run, who can prove it ran correctly, how is it paid for, and what happens when it fails halfway through?
Table of contents
- Cloud computing services are an operations decision, not a menu
- Why conventional clouds still dominate production
- Where centralized cloud computing services break down
- Decentralized compute as a complementary layer
- A reference architecture for decentralized cloud computing services
- Workload fit: AI inference, FFmpeg, and batch jobs
- Payments, identity, and trust are part of the compute system
- Operational controls that decide whether this works
- What works, what fails, and common failure modes
- How c0mpute.com fits into the stack
- Implementation checklist for builders evaluating cloud computing services
Cloud computing services are an operations decision, not a menu
The unit you buy is a workflow
The mistake teams make is treating cloud computing services as a catalog of machines. CPU count, GPU memory, storage class, and region matter, but they are not the system. The system is the path from request to result.
For a video platform, that path might be upload, probe, transcode, validate, publish, and bill. For an AI app, it might be prompt intake, model selection, inference, safety filtering, response streaming, cost attribution, and retry. For a web3 compute market, it also includes worker selection, reputation, payment, proof, and dispute handling.
A useful way to think about it is this: you are not buying servers. You are buying the ability to move a unit of work through a state machine with acceptable cost, latency, correctness, and failure behavior.
Practical rule: If you cannot draw the job state machine, you are not ready to compare cloud computing services.
This is why developer experience matters. A clean CLI can be more useful than a glossy dashboard if the CLI lets you package jobs, rerun failed work, inspect outputs, and automate deployment from a build pipeline.
The boundary is state, not servers
Infrastructure diagrams often show boxes: app server, queue, worker, object storage, database. That is useful, but incomplete. The hard boundary is where state changes ownership.
Who owns the input file? Who owns the intermediate artifact? Who signs the result? Who records that the worker should be paid? Who retries the job if the node disappears? These are state questions.
Centralized clouds hide some of that inside managed services. Decentralized compute makes it explicit. That is not a disadvantage if you design for it. It is a problem only when teams pretend the decentralized worker is just another VM.
Why conventional clouds still dominate production
They provide predictable control planes
Conventional cloud providers are not popular because every component is elegant. They are popular because the control plane is predictable. You can request capacity, attach permissions, stream logs, configure alerts, and get a support path when something fails.
That predictability is valuable. For core databases, low-latency APIs, compliance-heavy workloads, and persistent services, centralized cloud computing services still make sense. The scheduling model is mature, the operational defaults are familiar, and most engineers know how to debug the failure modes.
Related reading from our network: teams running distributed organizations face similar workflow design problems when choosing cloud based productivity and collaboration tools. The tooling category is different, but the operator lesson is the same: architecture beats tool lists.
They make boring operations easier
Boring operations are not a weakness. Backups, IAM, logs, networking, managed databases, and region failover are the reason production teams pay cloud bills.
What breaks in practice is assuming that the same abstraction works for every workload. A Kubernetes cluster is not automatically a good marketplace. A GPU instance is not automatically an inference product. A media worker is not automatically a transcoding pipeline.
The conventional cloud is good at owned infrastructure. Decentralized compute is interesting when the work is portable, verifiable enough, and economically sensitive to capacity markets.
Where centralized cloud computing services break down
GPU scarcity changes the economics
AI infrastructure builders already know the pattern. Demand spikes, GPU instances are constrained, reservations are expensive, and queue time becomes a product problem. If you are serving interactive inference, the user does not care that your provider is out of capacity in a preferred region.
The mistake teams make is solving this only with more commitments. Reserved capacity can be right for a baseline. It is less attractive for bursty workloads, experimental models, or long-tail jobs where latency tolerance varies by request.
A decentralized compute layer can help when jobs are dispatchable to workers with known capabilities. That does not mean every prompt should go to the cheapest machine. It means the routing layer should understand model size, GPU memory, expected latency, data sensitivity, and price.
Media workloads punish naive architecture
FFmpeg jobs look simple in a demo. In production they are mostly about edge cases: corrupt input, unsupported codecs, large files, subtitle handling, audio normalization, thumbnail extraction, multi-rendition output, and retries after partial completion.
Media also exposes a hidden cost center: movement. If a 4 GB file crosses the wrong boundary three times, the compute price is not the main issue. Storage locality, signed URLs, artifact lifecycle, and validation are the real architecture.
| Workload | Bad fit for naive cloud use | Better architecture |
|---|---|---|
| AI inference | One fixed GPU pool for every request | Route by model, latency, price, and trust |
| FFmpeg transcode | Upload to one region, process elsewhere, copy again | Package jobs near storage and validate outputs |
| Batch indexing | Long-running workers with idle time | Queue portable jobs across variable capacity |
| Web3 services | Treat payment as separate from execution | Bind identity, job state, and settlement |
Practical rule: For heavy media and AI jobs, price per machine-hour is less important than price per completed, validated result.
Decentralized compute as a complementary layer
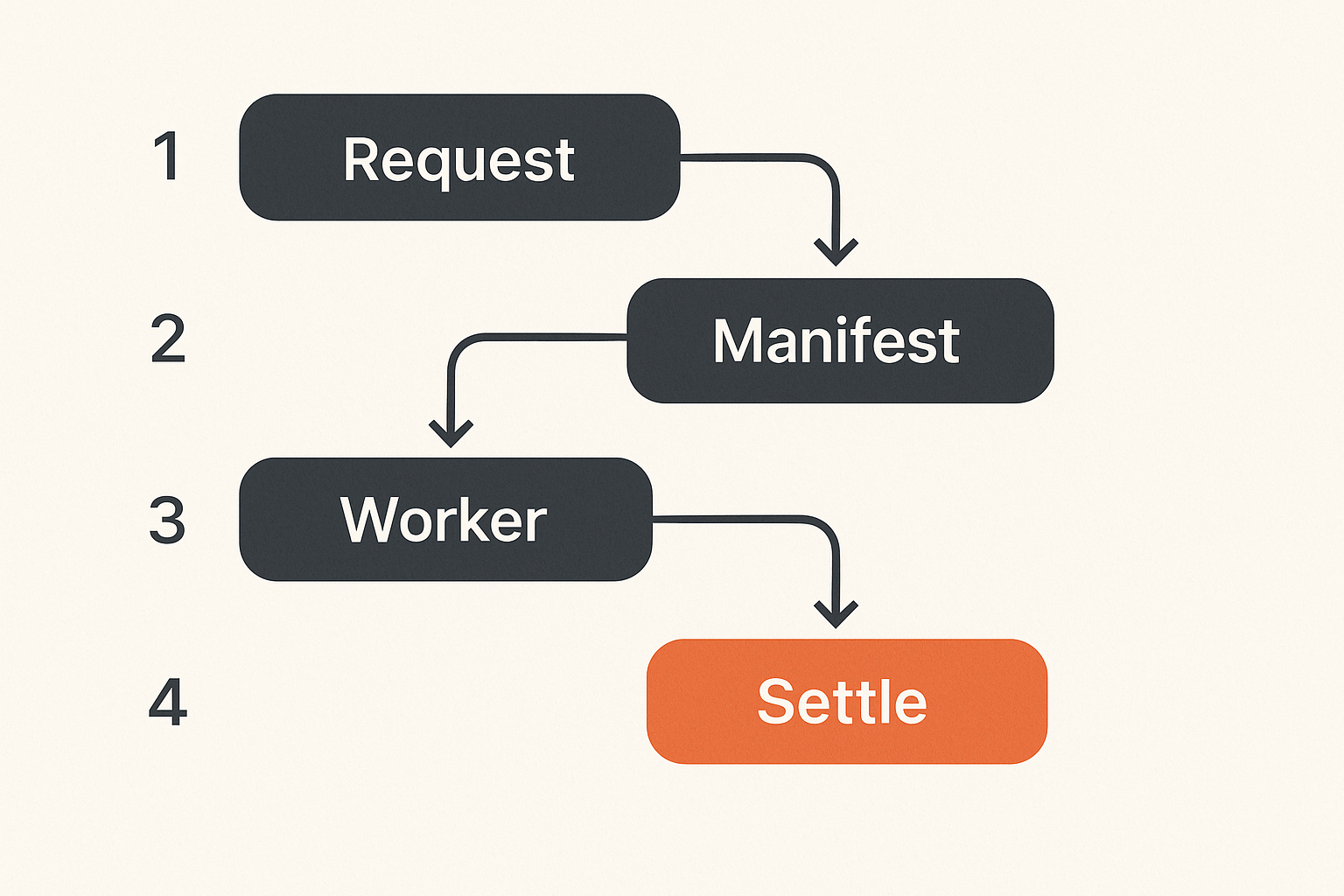
Do not replace the whole cloud
The hype version says decentralized compute replaces cloud providers. The operator version is more useful: decentralized compute extends where jobs can run.
You still need a control plane. You still need metadata storage. You still need authentication, artifact storage, monitoring, and support workflows. The difference is that execution can be delegated to a marketplace of workers when the workload is portable enough.
That changes the architecture from static ownership to dispatch. Instead of asking, how many machines should we own? you ask, which jobs must run on owned infrastructure, and which can run on external capacity under policy?
Push portable jobs to the edge of the system
Portable jobs have clear inputs, clear outputs, bounded runtime, retry behavior, and limited shared state. They are good candidates for decentralized compute.
Examples:
- Transcode this input into these renditions.
- Run this inference model against this prompt or batch.
- Generate embeddings for this dataset shard.
- Render these frames.
- Validate or transform this artifact.
Bad candidates are tightly coupled stateful services that require constant access to private databases, low-latency shared memory, or complex internal network dependencies.
Related reading from our network: platform workers and marketplace operators see a similar allocation problem in Upwork vs Fiverr for freelancers, where the real issue is matching scope, trust, pricing, and repeatability rather than picking a brand name.
A reference architecture for decentralized cloud computing services
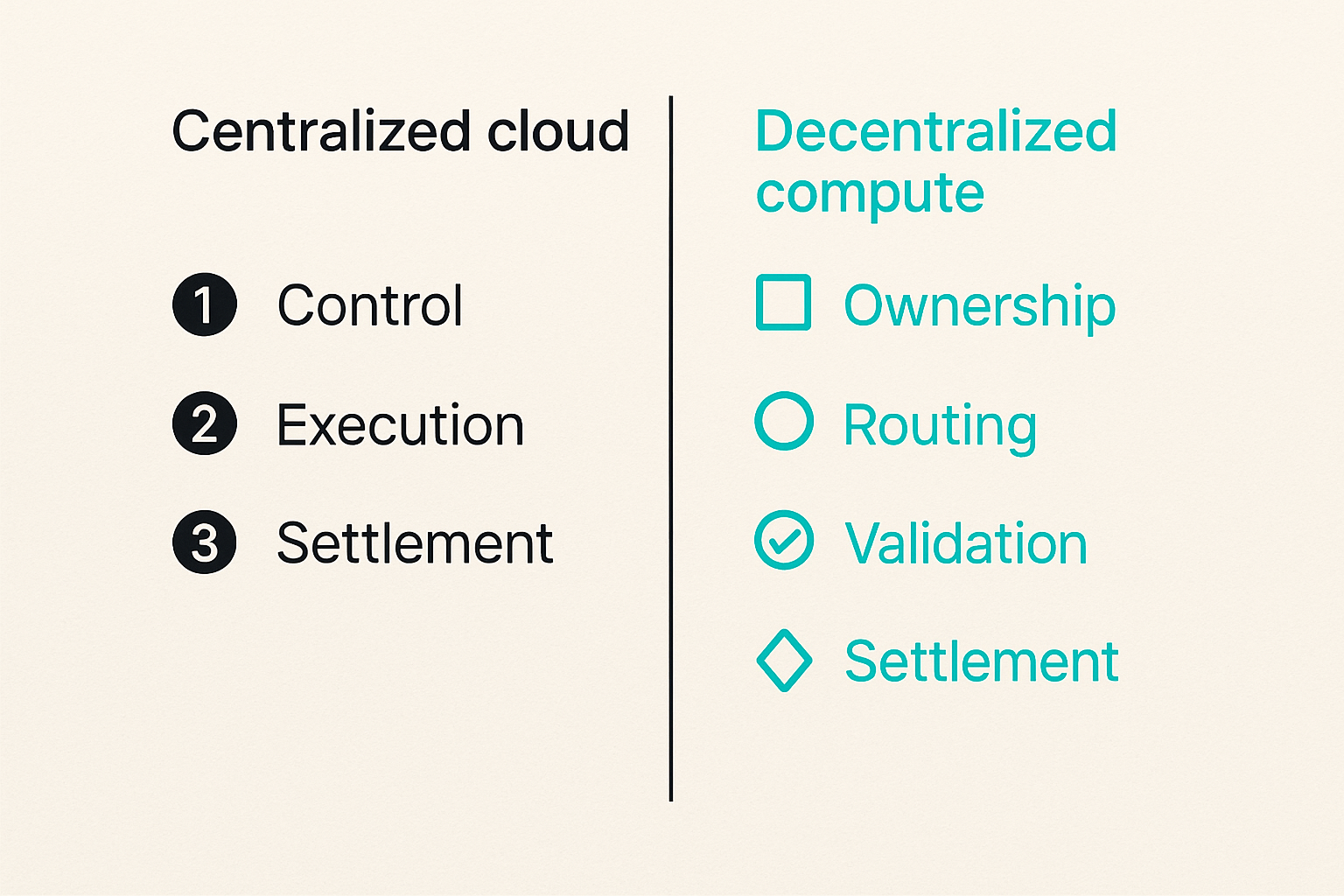
Separate control, execution, and settlement
A practical decentralized compute architecture has three planes:
- Control plane: accepts requests, validates policy, creates job records, assigns work, and tracks state.
- Execution plane: runs the actual workload on workers, nodes, or providers.
- Settlement plane: handles identity, payment, escrow, reputation, and dispute data.
Do not blur these. If the execution worker also decides payment eligibility without validation, you have a trust problem. If payment clears before output validation, you have a support problem. If the control plane does not know whether payment succeeded, you have a reconciliation problem.
For builders who want concrete commands instead of architecture theory, the c0mpute CLI reference and cookbook is the right place to map these ideas into install, identity, workers, transcode jobs, AI inference, reputation, plugins, and health checks.
Make every job idempotent
Idempotency is not optional. Workers will disappear. Clients will retry. Payment callbacks may arrive late. Output uploads can fail after compute completes.
A job should have a stable identifier, a content-addressed or versioned input reference, an expected output contract, and a retry policy. If the same job is submitted twice, the system should either return the existing result or create a new attempt under the same parent job.
A minimal job record might look like this:
job_id: job_8f31
kind: ffmpeg_transcode
input_uri: s3-compatible://bucket/video.mov
input_hash: sha256:abc123
profile: hls_1080p_720p_480p
max_attempts: 3
payment_policy: escrow_before_start
validation: probe_outputs_and_hash_manifest
state: queued
The important part is not the syntax. The important part is that job identity, input identity, output expectation, and payment policy live together.
Practical rule: A retry without idempotency is not reliability. It is a duplicate-work generator.
Workload fit: AI inference, FFmpeg, and batch jobs
AI inference needs routing, not just GPUs
AI inference is not one workload. A small text model, a diffusion model, a long-context LLM, and an embedding job all behave differently. They have different memory profiles, latency sensitivity, batching behavior, and output validation options.
The practical question is how requests are routed. A good router considers:
- Model requirements and worker capability.
- Cold start and queue depth.
- Price ceiling per request.
- Trust level of the worker.
- Data sensitivity and retention policy.
- Whether the request is interactive or batch.
For interactive inference, decentralized workers may be best as overflow, regional capacity, or specialized model providers. For batch inference, they can become primary execution capacity if validation and retry are strong enough.
FFmpeg needs deterministic job packaging
FFmpeg is powerful because it is explicit. That also means your system has to be explicit. Pin versions where possible. Store command templates. Capture stderr. Save manifests. Validate outputs with ffprobe or equivalent checks.
A CLI-first transcode job should be reproducible from a manifest:
c0mpute transcode submit \
--input ./source.mov \
--profile hls-abr \
--output ./dist/video-001 \
--max-attempts 3
The command is only the front door. Behind it, the platform still needs upload handling, job state, worker matching, artifact validation, and payment settlement.
Payments, identity, and trust are part of the compute system
DID-based identity changes worker reputation
In a normal cloud account, identity is usually account-based. In decentralized compute, identity has to travel across participants. DID-based identity is useful because it gives workers and clients a persistent cryptographic identity that is not just an email login.
Reputation can then attach to worker behavior: completed jobs, failed validations, dispute history, response time, supported hardware, and declared capabilities. This is not magic. Reputation systems can be gamed. But without identity, every scheduling decision starts from zero.
The mistake teams make is bolting reputation on later. By then, job records, payment records, and worker records often use different identifiers. Matching them becomes a data cleanup project.
Payment events must match compute events
Compute marketplaces fail when payment state and job state drift apart. A client believes they paid. A worker believes they completed the job. The platform has an output artifact but no settlement record. Support has to reconstruct the timeline from logs.
Design the state machine so payment events are first-class:
- Payment authorized.
- Escrow funded.
- Worker assigned.
- Output submitted.
- Validation passed.
- Settlement released.
- Dispute opened, if needed.
This is why DID-based payments, escrow rules, and compute orchestration belong in the same architecture conversation. They do not have to live in the same service, but they must share identifiers and lifecycle events.
Related reading from our network: SaaS buyers dealing with integration-heavy operations hit a comparable issue in automation direct workflow design, where the failure is usually disconnected state rather than missing features.
Operational controls that decide whether this works

Health checks are product features
Health checks are not just for internal dashboards. In a compute marketplace, health affects routing, pricing, support, and trust.
A worker health model should include:
- Heartbeat freshness.
- Available CPU, GPU, memory, and disk.
- Supported runtimes and versions.
- Recent job success rate.
- Validation failure rate.
- Network reachability.
- Queue depth.
If health is vague, the scheduler becomes guesswork. If health is precise, routing can be policy-driven. For live network visibility, builders should treat a public network status page as part of the operating surface, not a marketing artifact.
Observability must follow the job
Logs tied only to machines are not enough. In decentralized compute, the machine may be outside your direct control. Observability has to follow the job.
Each job attempt should carry correlation identifiers across API calls, worker logs, artifact uploads, validation steps, and settlement events. When support investigates a failed inference or transcode, they should not grep five systems manually.
A useful job timeline looks like this:
12:00:01 job.created
12:00:03 payment.escrow_funded
12:00:08 worker.assigned did:worker:71f
12:00:12 input.download_started
12:01:44 execution.completed
12:01:51 output.uploaded
12:02:02 validation.passed
12:02:05 settlement.released
What works is boring traceability. What fails is trusting worker logs as the only source of truth.
What works, what fails, and common failure modes
What works in production
The teams that get value from decentralized cloud computing services usually follow a conservative pattern. They keep critical state in a reliable control plane. They send portable work to external capacity. They validate outputs before settlement. They keep retries bounded. They expose enough observability to support users without heroic debugging.
What works:
- Start with one workload class, not the whole platform.
- Use explicit job manifests.
- Keep input and output contracts small and testable.
- Prefer content hashes and immutable artifacts.
- Separate worker identity from worker claims.
- Route based on capability, history, and price.
- Treat failed validation as normal, not exceptional.
This is less exciting than saying the cloud is dead. It is also more likely to survive contact with production.
What breaks in practice
What breaks in practice is usually not the cryptography or the scheduler algorithm. It is the operational glue.
Common failure modes include:
- Jobs cannot be retried safely because inputs changed.
- Workers claim capabilities the scheduler never verifies.
- Payment succeeds but job state remains pending.
- Output artifacts are overwritten by duplicate attempts.
- Logs are machine-centric instead of job-centric.
- Validation is manual, inconsistent, or skipped under load.
- Support cannot explain why a worker was selected.
- Pricing is shown before storage, egress, or retry cost is known.
Practical rule: Decentralized compute should increase execution options, not increase uncertainty for the user.
The operator test is simple: can a developer submit a job, watch state transitions, inspect failures, reproduce the command, and understand the final charge? If not, the marketplace is not ready for serious workloads.
How c0mpute.com fits into the stack
A CLI-first compute marketplace
c0mpute.com is built around a practical assumption: technical builders want programmable compute workflows, not another abstract cloud console. The network focuses on decentralized compute for AI inference, FFmpeg transcoding, and DID-based payments.
That makes it relevant for CLI-first developers who need to package jobs, run workers, test inference paths, and connect execution to settlement. The point is not to pretend that every workload belongs on a decentralized network. The point is to make the workloads that do fit easier to submit, route, validate, and pay for.
You can think of the platform as three connected modules:
| Module | Primary job | Architecture concern |
|---|---|---|
| transcode | FFmpeg media processing | Deterministic commands, artifacts, validation |
| infernet | AI inference | Model routing, GPU capability, latency |
| coinpay | DID-based payments | Identity, escrow, settlement, reputation |
Where it belongs in your architecture
c0mpute.com fits best as an execution and settlement layer beside your existing application stack. Your app still owns product state, user accounts, business logic, and policy. The compute network handles selected jobs that can be described, dispatched, and validated.
A typical integration path looks like this:
- Your app creates a job manifest.
- The manifest references input artifacts and expected outputs.
- c0mpute routes the job to a capable worker.
- The worker executes the job and submits outputs.
- Validation checks the result.
- Payment settlement follows the validated outcome.
- Your app consumes the final artifact or inference result.
That boundary keeps the system understandable. You do not outsource your product. You outsource specific execution paths under explicit contracts.
Implementation checklist for builders evaluating cloud computing services
A 10-step evaluation workflow
If you are comparing cloud computing services in 2026, include decentralized compute in the evaluation only where it changes the operating model. Do not add it because the architecture diagram looks modern.
Use this workflow:
- Pick one workload: inference, transcode, embedding, render, or batch transform.
- Write the job state machine from submitted to settled.
- Define input ownership, output ownership, and artifact retention.
- Decide what must be validated automatically.
- Set retry limits and idempotency keys.
- Define worker capability requirements.
- Connect payment state to job state.
- Add job-level logs and correlation IDs.
- Run failure tests: worker loss, duplicate callback, bad output, late payment event.
- Compare cost per validated result, not raw instance price.
A simple policy file can make the evaluation concrete:
policy:
workload: ai_inference_batch
max_price_per_job: 0.80
max_attempts: 2
require_worker_reputation: medium
validation: schema_and_sample_check
settlement: release_after_validation
fallback: centralized_gpu_pool
The best architecture is rarely all centralized or all decentralized. It is usually a routing decision. Baseline capacity may stay on conventional cloud computing services. Bursty, portable, or marketplace-friendly jobs can move to decentralized compute. Sensitive or tightly coupled state should stay close to systems you control.
Cloud computing services are becoming less about where a server lives and more about how work moves through policy, execution, validation, and settlement. For AI infrastructure builders, video engineers, and web3 developers, that is the useful frame.
Try c0mpute.com
c0mpute.com is for technical builders interested in decentralized compute, AI inference, FFmpeg transcoding, and DID-based payments. If you are evaluating cloud computing services for portable workloads, Try c0mpute.com.