AI agents cloud computing sounds like a capacity problem until the first production workflow stalls halfway through a job. The agent planned correctly. The model call worked. The UI showed progress. Then a worker timed out, a video segment was lost, a webhook retried twice, and nobody could tell whether the job was safe to resume.
Teams think the problem is getting agents access to more cloud resources. The real problem is giving agents a reliable execution layer: scheduling, state, identity, validation, payment, and recovery across machines they do not directly own.
That changes the conversation. Instead of asking which model is smartest, the practical question is where the agent should run work, how outputs are verified, who pays for compute, and what happens when the agent is wrong, slow, or interrupted.
For web3 developers, AI infrastructure builders, video engineers, and CLI-first teams, this is where decentralized compute becomes interesting. Not as a replacement for every cloud service, but as an execution market for jobs that can be packaged, priced, routed, checked, and settled.
Table of contents
- Why AI agents cloud computing is an architecture problem
- From prompt to job graph
- Centralized cloud versus decentralized compute for agent workloads
- Design the agent compute control plane
- State, identity, and payments for autonomous jobs
- Inference and video workloads are good first targets
- Reliability means retries, idempotency, and validation
- Security boundaries for agent-run compute
- Observability and cost controls for AI agents cloud computing
- Implementation workflow for a CLI-first team
- What breaks when teams implement this badly
- Where c0mpute.com fits
Why AI agents cloud computing is an architecture problem
AI agents cloud computing is usually sold as a scale story: agents will call tools, launch workloads, and consume cloud capacity automatically. That is directionally true, but incomplete.
The mistake teams make is treating the agent as the system. In production, the agent is only the decision layer. The system is the queue, the compute market, the worker contract, the artifact store, the validator, the payment rail, and the recovery path.
Agents do not need servers, they need execution contracts
A server is an implementation detail. An execution contract is what the agent can rely on.
For an autonomous job, the contract should answer:
- What input schema is accepted?
- What runtime is required?
- What maximum duration is allowed?
- What artifacts must be returned?
- What status transitions are valid?
- What does the worker get paid for?
- What evidence proves the work completed?
Without that contract, the agent is just throwing commands into a black box. It may work in a demo. It will break under retries, multiple workers, partial outputs, and user disputes.
Practical rule: never let an agent launch compute unless the work can be described as a bounded job with explicit inputs, outputs, limits, and validation.
The old cloud assumption breaks at agent speed
Traditional cloud workflows assume humans design the infrastructure, deploy services, and inspect failures. Agents invert part of that model. They generate tasks dynamically, route them to tools, and may create many small jobs as part of one larger goal.
That creates pressure in places ordinary app teams sometimes ignore:
- Job fan-out grows faster than request traffic.
- Failed sub-tasks are hard to reason about from the final UI state.
- Cost can accumulate through retries rather than visible user actions.
- Tool permissions become a runtime security boundary.
- Compute selection becomes part of product behavior.
What breaks in practice is not the model call. It is the handoff between intent and execution.
Decentralized compute changes the routing decision
A useful way to think about decentralized compute is not cheaper cloud, but externalized execution capacity with market pricing and explicit settlement. That matters for agent systems because many agent tasks are intermittent, bursty, and job-shaped.
An AI coding agent may need to run tests in a clean environment. A media agent may need to transcode ten versions of a clip. A research agent may need to run OCR, embeddings, summarization, and extraction across a document batch. Keeping dedicated infrastructure warm for every possible path is wasteful.
Decentralized compute lets the control plane ask a better question: which jobs must stay in our controlled cloud, and which can be packaged and sent to a compute network with clear validation?
From prompt to job graph
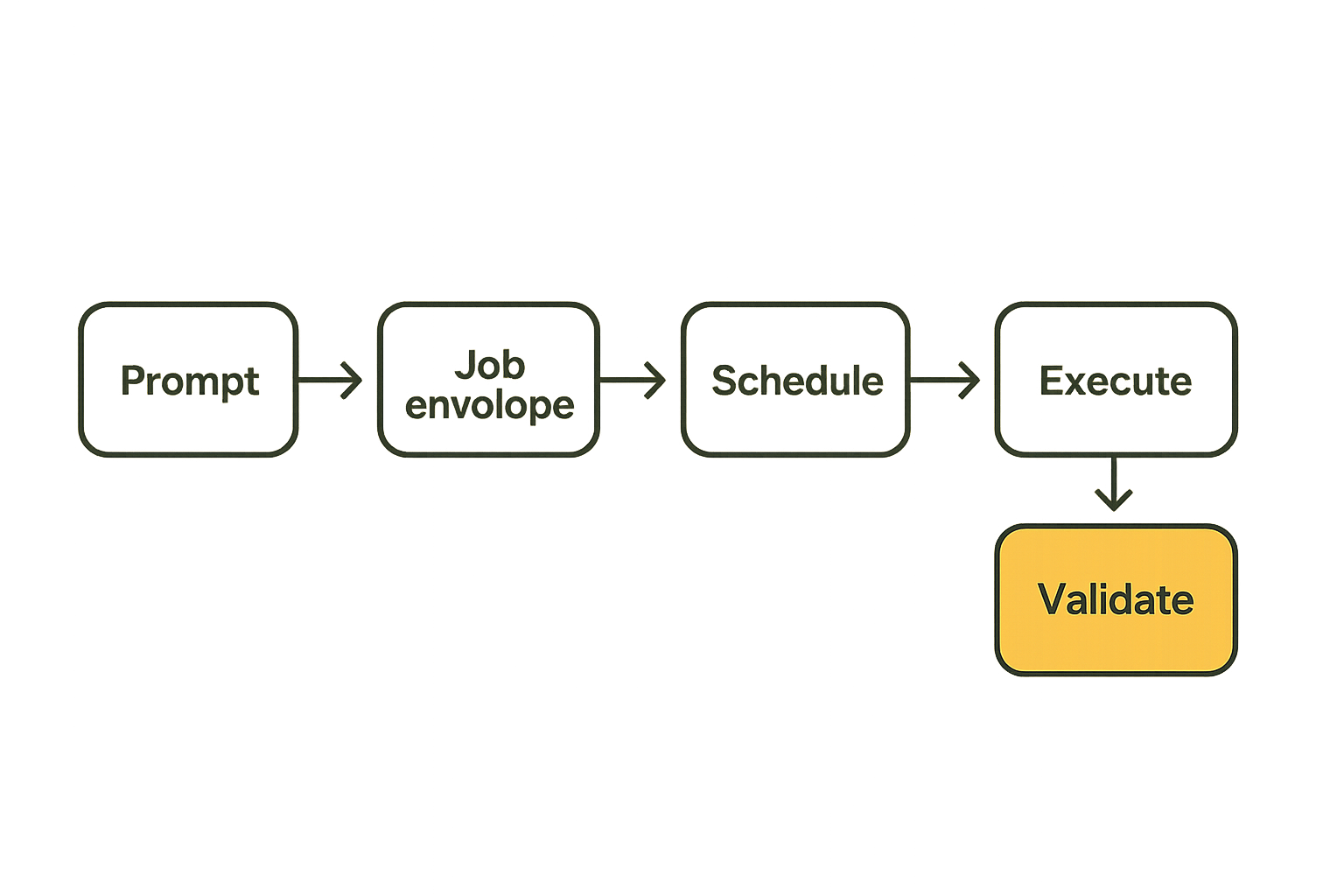
An agent prompt is not an execution plan. It is an instruction that may produce a plan. The cloud architecture should convert that plan into a job graph before anything expensive or stateful happens.
Planning is not execution
Agents are good at selecting steps. They are weaker at respecting operational boundaries unless the system gives them those boundaries.
A typical agent flow might look like this:
- User requests a result, such as summarize and clip this 40-minute video.
- Agent decomposes the request into transcription, scene detection, highlight selection, FFmpeg clipping, thumbnail generation, and final packaging.
- Control plane converts those steps into typed jobs.
- Scheduler routes each job to the right compute option.
- Validator checks outputs before the agent moves to the next step.
- Settlement records who performed which work and what was paid.
The agent can decide what should happen next, but the control plane decides how work is executed safely.
Jobs need portable envelopes
A portable job envelope is the difference between cloud glue and real infrastructure. It should include enough information for a worker to run the task without knowing your product internals.
Example envelope:
job_id: clip-8f31
kind: ffmpeg_transcode
input_uri: ipfs://source-video
output_spec:
format: mp4
resolution: 1080p
codec: h264
limits:
timeout_seconds: 900
max_output_mb: 700
validation:
min_duration_seconds: 30
required_streams:
- video
- audio
payment:
max_price: 2.50
currency: usdc
This is not complicated. The discipline is in refusing to launch vague work. If the agent cannot produce a bounded job envelope, it should ask a clarifying question or route the task back to a human-controlled path.
Results need machine-readable status
Agents should not scrape logs to infer success. Workers should return structured status:
job_id: clip-8f31
status: completed
artifact_uri: ipfs://output-video
runtime_seconds: 214
cost: 1.82
validator:
passed: true
checks:
- stream_layout
- duration
- file_size
This lets the agent continue safely. It also gives operators a clean record for debugging, billing, and dispute handling.
Practical rule: if a human has to open a dashboard to decide whether an agent job succeeded, the workflow is not autonomous yet.
Centralized cloud versus decentralized compute for agent workloads
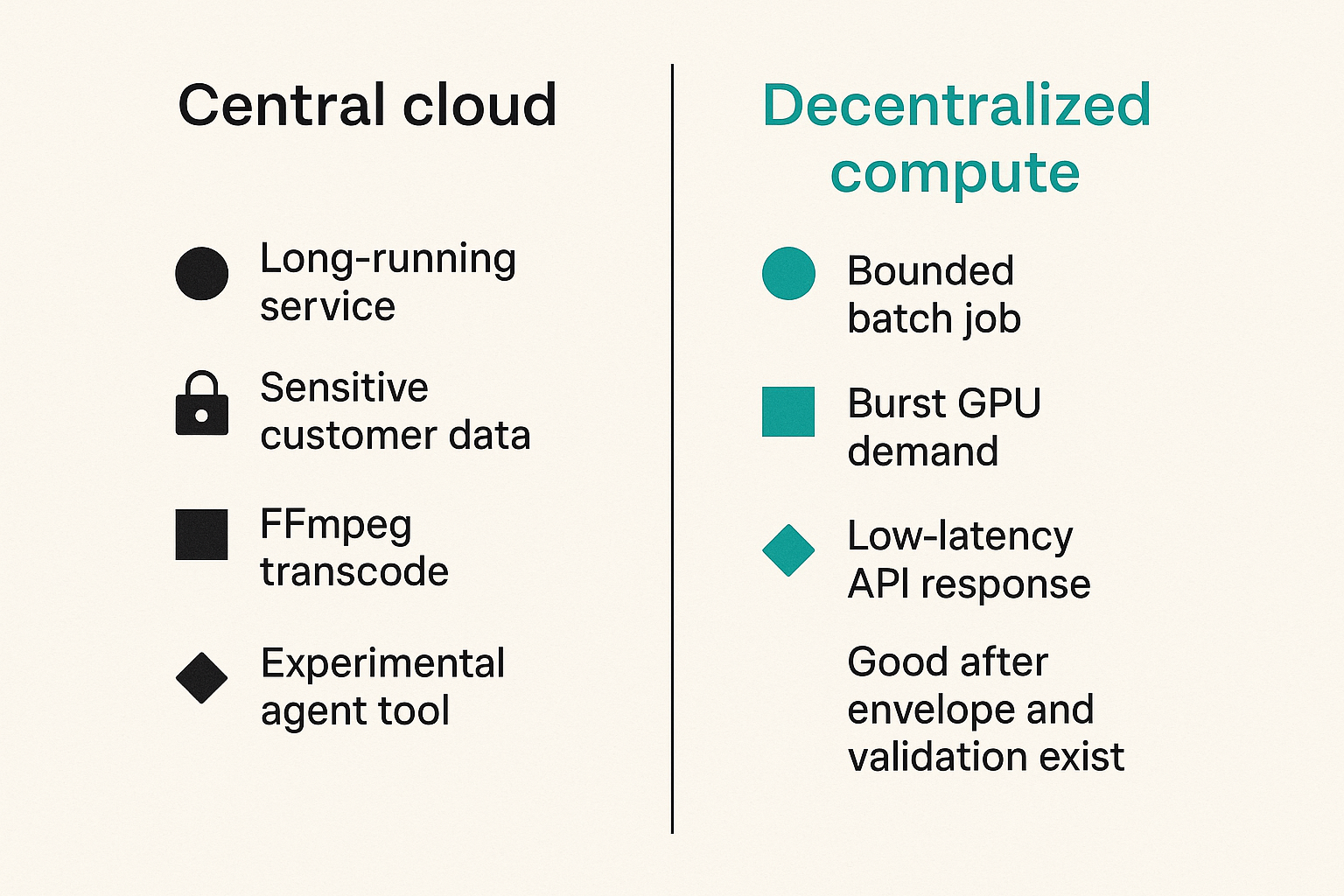
Teams often frame the decision as centralized cloud versus decentralized compute. That is the wrong framing. The better framing is workload placement.
Some agent jobs belong in your primary cloud. Some belong on specialized GPU providers. Some are good candidates for decentralized compute. Some should not run automatically at all.
Use placement rules, not ideology
A simple comparison helps:
| Workload characteristic | Primary cloud | Decentralized compute |
|---|---|---|
| Long-running service | Strong fit | Weak fit |
| Bounded batch job | Good fit | Strong fit |
| Sensitive customer data | Strong fit if controlled | Only with strong encryption and policy |
| Burst GPU demand | Often expensive or capacity-limited | Strong fit when validation is clear |
| FFmpeg transcode | Good fit | Strong fit |
| Low-latency API response | Strong fit | Depends on network and routing |
| Experimental agent tool | Good for early testing | Good after envelope and validation exist |
The practical question is not where compute is theoretically possible. It is where the job can finish reliably with acceptable latency, cost, trust, and auditability.
Latency-sensitive work has different constraints
If an agent is answering an interactive chat message, routing every step to an external compute network may be the wrong move. User-facing latency has a hard ceiling.
But many agent workloads are not truly synchronous:
- Generate video variants.
- Index a document library.
- Run code tests.
- Batch embeddings.
- Render previews.
- Extract frames.
- Evaluate model outputs.
These tasks can tolerate queueing if the system exposes progress and completion events. That is where decentralized compute becomes practical.
Cost is only useful when tied to completion
Cheap failed compute is expensive. A low unit price does not help if jobs time out, outputs are malformed, or the agent retries blindly.
For agent systems, cost should be measured per validated completion, not per attempted run. That means your scheduler needs to track:
- Accepted bid or quoted price.
- Runtime.
- Retry count.
- Validation result.
- Artifact availability.
- Final user-visible outcome.
That changes the conversation from raw infrastructure pricing to job economics.
Design the agent compute control plane
The control plane is where AI agents cloud computing becomes operable. It is the layer between agent reasoning and actual execution.
A minimal control plane has four jobs: accept work, enforce policy, route execution, and record outcomes.
The scheduler is the policy engine
The scheduler should not be a random worker selector. It should apply product and infrastructure policy:
- Which job kinds are allowed for autonomous execution?
- Which workers or networks are eligible?
- What is the maximum spend per user, agent, or workflow?
- What data can leave the primary environment?
- Which validation checks are required before completion?
- When should work be retried, split, or escalated?
For example, a scheduler might allow public video transcoding on decentralized compute, but require private customer training data to stay in a controlled cloud region.
Workers should expose a narrow interface
Workers do not need access to your whole app. They need the job envelope, input artifacts, runtime environment, and a way to return results.
A narrow interface reduces blast radius:
submit(job_envelope) -> accepted | rejected
status(job_id) -> queued | running | failed | completed
result(job_id) -> artifact_uri + metadata
cancel(job_id) -> cancelled | already_completed
This works across internal workers, cloud functions, Kubernetes jobs, and decentralized compute providers. The interface is more important than the backend.
Queues are the boundary between intent and work
The queue is where you turn agent intent into durable execution. Without a queue, the agent process becomes responsible for everything: state, retries, timeout handling, and recovery. That is brittle.
A good queue record includes:
- Job ID.
- Workflow ID.
- Agent ID.
- User or tenant ID.
- Input hash.
- Status.
- Attempt count.
- Selected worker.
- Cost ceiling.
- Deadline.
- Validation policy.
The queue also gives operators a place to intervene without editing prompts or redeploying the agent.
State, identity, and payments for autonomous jobs
Agent-run compute needs a clean answer to a basic question: who is allowed to spend money and move data?
The answer should not be hidden in a prompt or buried in an API key shared across the whole application. It should be explicit in identity, policy, and settlement records.
Agent identity should be separate from user identity
An agent may act on behalf of a user, but it should not be the user. Separate identity lets you express constraints:
- This user authorized this agent.
- This agent may spend up to a defined budget.
- This workflow may access only these artifacts.
- This job may run only on approved worker classes.
- This payment may settle only after validation.
This is especially important when agents chain tools. If every tool call uses the same broad credential, you lose the ability to explain or restrict behavior.
DID-based payments make compute permissions explicit
For decentralized compute networks, DID-based payments and signed job requests can make authorization visible. The worker sees that a job was submitted by a recognized agent identity with a specific payment condition. The control plane sees which identity approved spend.
This matters because agents will create more small economic events than traditional users. A human might click render once. An agent might split the render into 40 segments, retry 3, and request thumbnails for 12.
The payment system needs to understand the workflow, not just the wallet.
Settlement belongs in the workflow, not support tickets
Settlement should be tied to job state. A simple state machine might look like:
created -> priced -> accepted -> running -> completed -> validated -> settled
-> failed -> retried
-> disputed
The mistake teams make is treating payment as an afterthought. Then a worker claims completion, the app cannot find the artifact, the user wants a refund, and the operator has to reconstruct events from logs.
Practical rule: do not settle autonomous compute jobs until the artifact exists, validation passes, and the workflow state is updated.
Inference and video workloads are good first targets
Not every workload is a good starting point. The best early targets for AI agents cloud computing are jobs with clear boundaries and measurable outputs.
Inference and video infrastructure fit that pattern well.
LLM inference benefits from routing flexibility
Inference demand is uneven. Agents may need a small model for extraction, a larger model for reasoning, and an embedding model for retrieval. The best route can change based on cost, latency, context length, availability, and privacy.
A control plane can route inference based on policy:
- Use local or reserved capacity for latency-critical steps.
- Use external GPU capacity for batch generation.
- Use cheaper models for classification and extraction.
- Escalate only hard cases to larger models.
- Cache deterministic or low-temperature outputs.
This is less glamorous than a single giant model, but it is how many production systems stay usable.
FFmpeg transcoding is naturally job-shaped
Video work is a strong fit because it already has explicit inputs and outputs. An FFmpeg job can be described with source, codec, bitrate, resolution, duration, output container, and validation checks.
Example command generated from a job envelope:
ffmpeg -i input.mp4 -vf scale=1920:1080 -c:v libx264 -c:a aac output-1080p.mp4
The agent should not be trusted to invent arbitrary shell commands against production storage. The safer pattern is to let the agent choose from approved transform types, then have the control plane compile that choice into a worker-safe command.
Mixed pipelines need typed handoffs
Real workflows combine inference and media processing. A video agent might:
- Transcribe audio.
- Summarize transcript.
- Select highlight ranges.
- Clip segments with FFmpeg.
- Generate captions.
- Render final variants.
- Publish artifacts.
Each handoff should be typed. The clipper should receive timestamps, not a paragraph. The renderer should receive validated media assets, not a vague instruction. The publisher should receive artifact URIs and metadata, not local paths from a worker that may no longer exist.
Typed handoffs are what keep agent creativity from becoming infrastructure chaos.
Reliability means retries, idempotency, and validation
Reliability is not a single feature. It is a set of boring guarantees that prevent small failures from turning into user-visible messes.
The agent can retry a plan. The control plane must decide whether retrying is safe.
Every job needs an idempotency key
If the same job is submitted twice, should it run twice? Sometimes yes, usually no.
An idempotency key should be derived from stable job inputs:
hash(agent_id + workflow_id + job_kind + input_hash + output_spec)
This lets the system detect duplicates after network failures, process crashes, and webhook retries. It also prevents an agent from spending money twice for the same deterministic operation.
For non-deterministic jobs, such as creative generation, the key should include the seed or explicit run ID so the behavior is intentional.
Validation should happen before the agent continues
Validation does not have to mean perfect proof. It means checking the output before it becomes input to the next step.
For video, validation might check:
- File exists at artifact URI.
- Duration is within expected range.
- Audio and video streams are present.
- Resolution matches output spec.
- File size is below limit.
- Hash matches returned metadata.
For inference, validation might check:
- Output parses as expected JSON.
- Required fields exist.
- Confidence threshold is met.
- The response does not exceed policy limits.
- A cheaper verifier model agrees on basic structure.
The goal is not to eliminate all errors. The goal is to stop bad outputs from silently poisoning later steps.
Failure domains must be visible
When a workflow fails, operators need to know which layer failed:
- Agent planning.
- Job creation.
- Scheduling.
- Worker execution.
- Artifact storage.
- Validation.
- Payment.
- Callback delivery.
If every failure is just agent failed, the system cannot improve. You will tune prompts when you should fix retries. You will change workers when validation is wrong. You will blame the compute network when your artifact store expired the input.
Security boundaries for agent-run compute
AI agents make security boundaries more important, not less. The agent is a planner with tool access. That is useful. It is also a new way to connect user input, automation, credentials, and compute.
The team at logicsrc.com has seen this same pattern in interoperable agent systems: the hard part is not making agents call tools, it is constraining those calls so the surrounding platform remains predictable.
Prompts are not permission systems
A prompt can say do not access private files. That is not a security boundary. A worker, token, policy engine, or storage layer must enforce it.
Use prompts for guidance. Use infrastructure for control.
Good boundaries include:
- Scoped artifact URLs.
- Short-lived credentials.
- Per-job secrets.
- Network egress limits.
- Worker allowlists.
- Explicit tool permissions.
- Budget caps.
If a malicious input can convince the agent to request a forbidden job, the scheduler should reject it.
Sandbox untrusted code and media
Agents often handle untrusted inputs: uploaded videos, archives, documents, code repositories, and URLs. Workers should assume inputs are hostile.
For media and code workloads, use sandboxing practices:
- Run jobs in isolated containers or VMs.
- Mount inputs read-only.
- Write outputs to a dedicated path.
- Disable unnecessary network access.
- Limit CPU, memory, disk, and runtime.
- Scan or validate outputs before publishing.
This is standard infrastructure hygiene. Agent systems make it easier to forget because the workflow feels high-level.
Treat model tools like production credentials
If an agent can call a tool that spends money, moves data, or publishes content, that tool is a production credential. It needs the same seriousness as an API key.
At minimum:
- Log every tool invocation.
- Bind tool access to agent identity.
- Enforce tenant boundaries outside the model.
- Require approvals for high-impact actions.
- Rotate credentials and revoke compromised agents.
The model should never be the only thing deciding whether an action is allowed.
Observability and cost controls for AI agents cloud computing
Observability for AI agents cloud computing has to connect model behavior with compute behavior. Token logs alone are not enough. Infrastructure metrics alone are not enough.
You need traces that show why work was created, where it ran, what it cost, and whether the result was useful.
Track job economics, not just token usage
For each workflow, track:
- Model tokens and model cost.
- Compute job attempts.
- Validated completions.
- Worker runtime.
- Queue latency.
- Artifact storage cost.
- Retry cost.
- Settlement amount.
- User-visible completion.
A workflow with cheap model calls can still be expensive if it launches too many compute jobs. A workflow with high GPU cost can still be profitable if it produces a valuable completed artifact with few retries.
The unit that matters is not request. It is completed workflow.
Debug with traces across model and compute steps
A useful trace should connect:
user request -> agent plan -> job envelope -> scheduler decision -> worker run -> artifact -> validation -> settlement -> response
This gives developers a way to answer practical questions:
- Did the agent create the right job?
- Did the scheduler choose the right backend?
- Did the worker fail or did validation reject the output?
- Did retries happen because of timeout, network, or bad input?
- Did the user see progress while work was running?
Without this trace, teams end up debugging distributed systems through chat transcripts.
Budgets should be enforceable at runtime
Budget controls must stop work before spend happens. Monthly reports are too late for autonomous systems.
Enforce budgets at several levels:
- Per job maximum price.
- Per workflow maximum spend.
- Per user or tenant daily cap.
- Per agent tool budget.
- Per worker class limit.
- Retry budget.
When the budget is exhausted, the agent should receive a structured response and choose a lower-cost path, ask the user, or stop.
Practical rule: an agent budget that only appears in analytics is not a budget. It is a postmortem field.
Implementation workflow for a CLI-first team
The fastest way to build this is not to start with a huge platform. Start with one workload that developers already understand from the command line.
Then wrap it with the minimum control plane needed to make it safe for agents.
Start with one repeatable workload
Pick a job with clear inputs and outputs. Good candidates:
- Transcode a video to a fixed profile.
- Generate embeddings for a document batch.
- Run tests for a repository snapshot.
- Convert images to thumbnails.
- Run OCR on uploaded PDFs.
- Execute a bounded inference batch.
Avoid starting with open-ended tasks like improve this application or research this market. Those can come later. First prove that the execution layer works.
Build the thin adapter first
A thin adapter turns a job envelope into an executable command and returns structured status.
For example:
agentctl submit ./jobs/transcode-1080p.yaml
agentctl status clip-8f31
agentctl result clip-8f31 --json
Behind that CLI, the adapter can target local Docker, your cloud, or a decentralized compute network. Developers get a stable workflow while infrastructure evolves.
A practical implementation sequence:
- Define the job envelope schema.
- Build a local worker that runs one job kind.
- Add artifact upload and result metadata.
- Add validation checks.
- Add queue state and retries.
- Add scheduler policy.
- Add decentralized compute as another backend.
- Add payment and settlement records.
- Expose the workflow to the agent as a constrained tool.
This order matters. If you expose the tool to the agent before validation and idempotency exist, you will create noisy failures that look like model problems.
Promote only after replay works
Before giving the agent more autonomy, make sure any workflow can be replayed from records.
Replay means you can take the stored job envelope, input artifact reference, scheduler decision, and validation policy, then reproduce or explain the outcome. It does not always mean bit-for-bit deterministic output, especially with model calls, but it should be operationally understandable.
If replay does not work, support will struggle. So will billing, security review, and worker dispute resolution.
What breaks when teams implement this badly
Most failures are not exotic. They are ordinary distributed-systems failures hidden behind agent language.
The agent seems intelligent, so teams skip the boring parts. Then production reminds them that autonomy without control is just a faster way to create inconsistent state.
The agent becomes a distributed cron job
A bad agent system launches background tasks with no durable state, no job ownership, and no clear recovery path. It is cron with better copywriting.
Symptoms include:
- Jobs disappear when the agent process restarts.
- Users resubmit requests because progress is unclear.
- Workers complete tasks after the workflow already failed.
- Duplicate artifacts appear.
- Costs spike from hidden retries.
What works is a queue-backed control plane with explicit workflow state.
No one owns failed work
When a job fails, is it the agent team, infrastructure team, worker provider, payments layer, or product team? If ownership is unclear, every incident becomes a meeting.
Assign ownership by layer:
- Agent planning failures belong to the agent/tooling team.
- Invalid job envelopes belong to the integration owner.
- Scheduling failures belong to the control plane owner.
- Worker runtime failures belong to the compute backend owner.
- Validation failures belong to the workload owner.
- Settlement failures belong to the payments owner.
This sounds bureaucratic, but it shortens incidents. It also makes reliability work measurable.
Outputs are accepted without proof
The fastest way to ship is to trust the worker response. The fastest way to regret it is to build downstream behavior on unvalidated outputs.
Bad patterns:
- Marking work complete when a callback arrives.
- Publishing artifacts before checking them.
- Paying for work before validation.
- Letting the agent summarize missing or partial files.
- Treating logs as proof of completion.
What works is boring: artifact checks, schema checks, status transitions, and settlement after validation.
Where c0mpute.com fits
For builders evaluating AI agents cloud computing in 2026, the useful question is not whether every workload should move to a decentralized compute marketplace. It should not.
The useful question is which agent jobs are bounded, portable, price-sensitive, and verifiable enough to run outside your primary infrastructure.
Use decentralized compute for bounded jobs
c0mpute.com is a fit when the workload can be packaged as a clear job: AI inference, FFmpeg transcoding, batch media processing, or other compute tasks where inputs, outputs, limits, and payment conditions are explicit.
That makes it relevant for:
- Agent systems that need burst execution capacity.
- Video platforms that need flexible transcoding.
- AI apps that need inference routing options.
- CLI-first developers who want programmable compute jobs.
- Web3 applications that need DID-aware payment flows.
The point is not to hide infrastructure. The point is to expose the right abstraction: submit work, track state, validate artifacts, and settle.
Keep orchestration close to your product
Even when execution is decentralized, orchestration should stay close to your product. Your application understands users, permissions, budgets, workflow state, and support expectations.
A clean split looks like this:
- Product owns user intent and workflow state.
- Agent owns planning within constrained tools.
- Control plane owns policy and scheduling.
- c0mpute.com provides decentralized execution capacity.
- Validators decide whether outputs are acceptable.
- Payment logic settles only after accepted completion.
That split keeps autonomy useful without giving the agent uncontrolled access to compute and funds.
Try c0mpute.com
Build agent-ready compute workflows for inference, FFmpeg transcoding, and decentralized execution with DID-based payments. Try c0mpute.com and start with one bounded job that your agents can submit, track, validate, and settle.